37 KiB

题库使用指南2024年5月版
本教程中的默认文件夹是题库根目录/工具v3
注意事项
所有同志可以放心大胆地在自己的电脑上进行任何操作, 不用担心产生严重的破坏性后果.
目前的题库数据是保存在搭建在NAS上的一个MySQL数据库中的, 每六个小时会作一次全量备份得到压缩文件, 每天会把这些压缩文件备份到其他地方, 所以即使误操作了, 损失也不会太大
在远程服务器上的master分支只有管理员有权限修改. 退一步说, 即使远程服务器上的master分支不慎被改错了, 返回到某一个历史版本也只是一条命令的事情.
原则上题库内容中不出现全角的句号(。)、逗号(,)、冒号(:)、问号(?)、感叹号(!)、小括号(())等
在文本中, 半角的标点符号后面一般应该有半角的空格或是直接换行
如果运行程序报错, 在联系管理员之前, 可以先试试和master同步, 随后在进入面板, 再退出面板之后输入cd ..(回到题库根目录), pip install -r requirements.txt, 或许安装一些python的package之后, 问题就解决了.
使用题库必要的软件安装
要使用题库, 比较典型的是在windows环境下, 以下四个软件是必须要安装的:
- git (版本管理): git下载界面 选择
64-bit Git for Windows Setup - vscode (代码编辑): vscode下载界面 选择
Windows - anaconda (python环境管理): anaconda下载界面 选择页面左侧中下方绿色的
Download - texlive (LaTeX环境): texlive上海交大镜像下载界面 选择
texlive.iso
其中git的下载可能会不顺利, 因为下载的地址在众所周知难以访问的github.com上, 也可以到 我们自己网盘上的镜像下载. 自己的网盘上虽然四个软件都有, 但是事实上texlive不建议大家在自己这里下, 因为太慢了
下载完成之后按照任意排列安装这四个软件即可, 安装路径中必须没有中文, 也没有空格. 其他的都按照安装程序默认的方式即可. anaconda的安装大约需要10分钟左右, texlive可能要30至120分钟, 都是因为小文件非常多.
打开面板的方式
在配置好python的math环境, 在题库根目录运行过pip install -r requirements.txt, 并且编写过conda_initiate.bat之后(编写conda_initiate.bat的工作请联系管理员), 在cmd终端的题库根目录运行conda_initiate.bat, 会跳出一个PySide6做的GUI面板.
如果面板还没有跳出来, 随后在终端依次输入cd 工具v3回车, python 工具面板.py回车, 就会跳出一个tkinter做的GUI面板.
在overleaf上协作编辑
我们自己部署的本地overleaf服务器的地址是overleaf kongjiang(kjwangweiye.top:40388)或overleaf kongjiang mirror(wwylss.synology.me:40388)
如果还未注册过, 请联系管理员, 提供一个邮箱(可以是真实的邮箱, 也可以不是)以新建账号(之后首次登录会要求设置密码, 请不要忘记邮箱和密码)
万一忘记了邮箱和密码就只能删除账号重新再开了, 服务器上属于该账号的所有工作就一并被删除了.
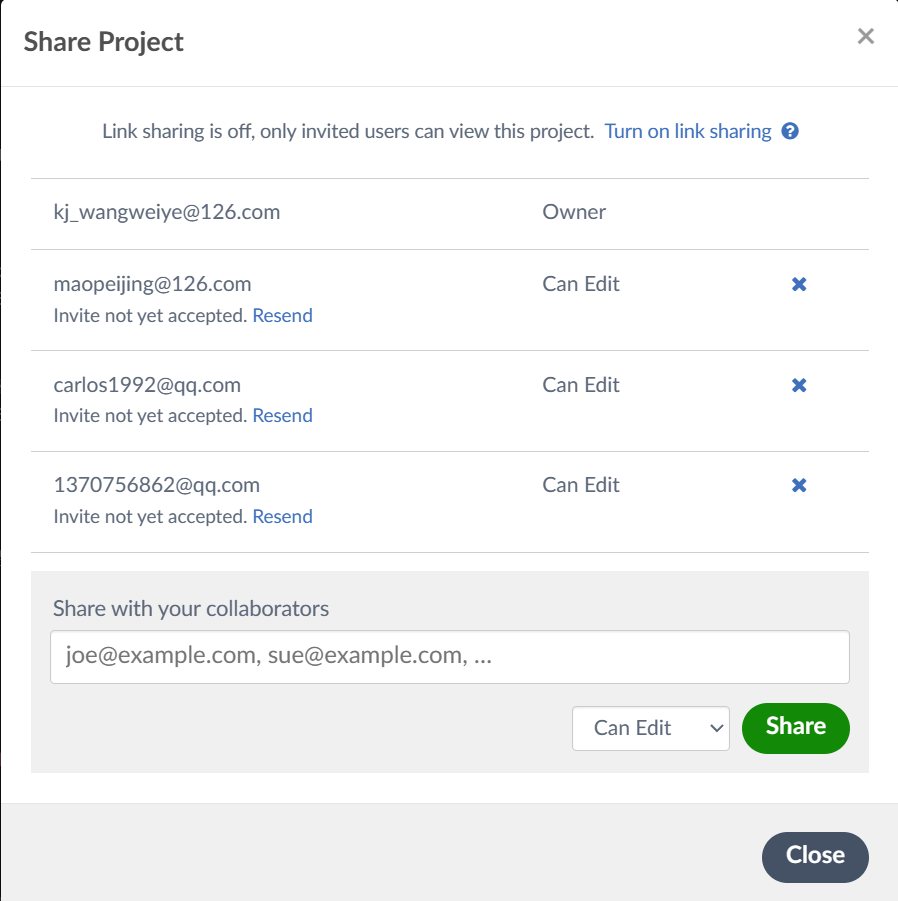
知道对方的邮箱的话, 可以在overleaf上邀请对方参加协作, 一起编辑同一个项目.
在gitlab上提交issue
我们自己部署的本地gitlab服务器的地址是gitlab(wwylss.synology.me:30000)
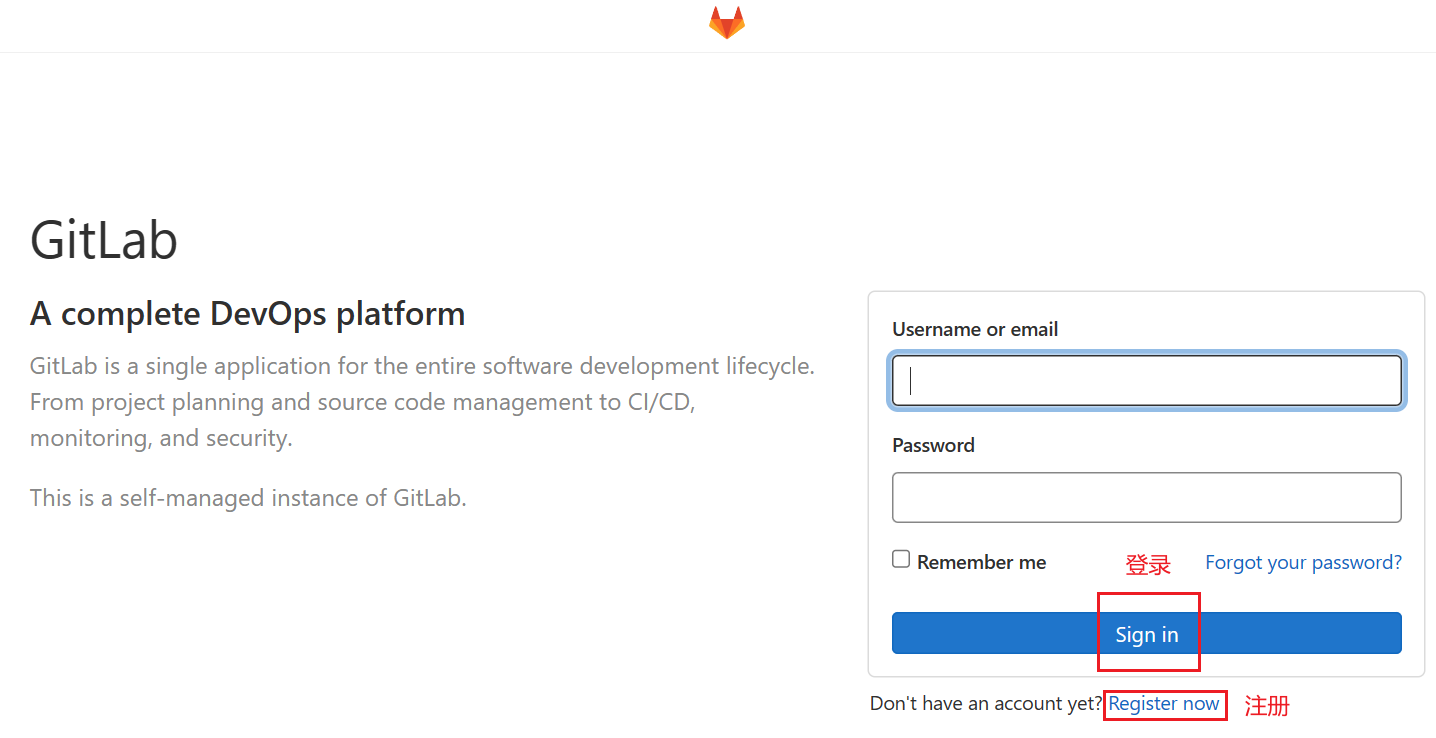
如果还未注册过, 请在上述界面中注册, 并联系管理员以通过注册.
一个较大的项目的协作者之间的工作联系通常不是通过微信、电话这种追溯历史不太方便的方式实现的. gitlab提供了一个比较有效的方式: 提交issue(问题/事件)
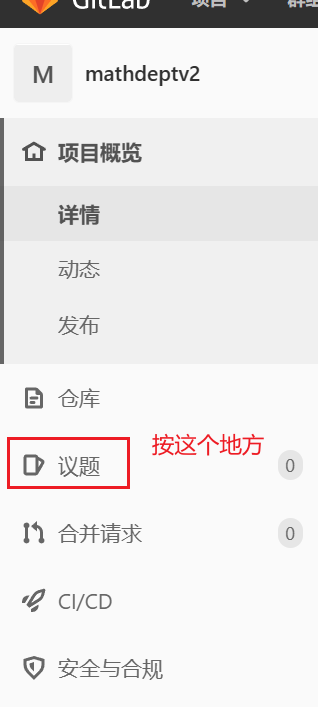
上图就是提交issue的按钮, 点击后选择新建议题, 会显示下面的界面
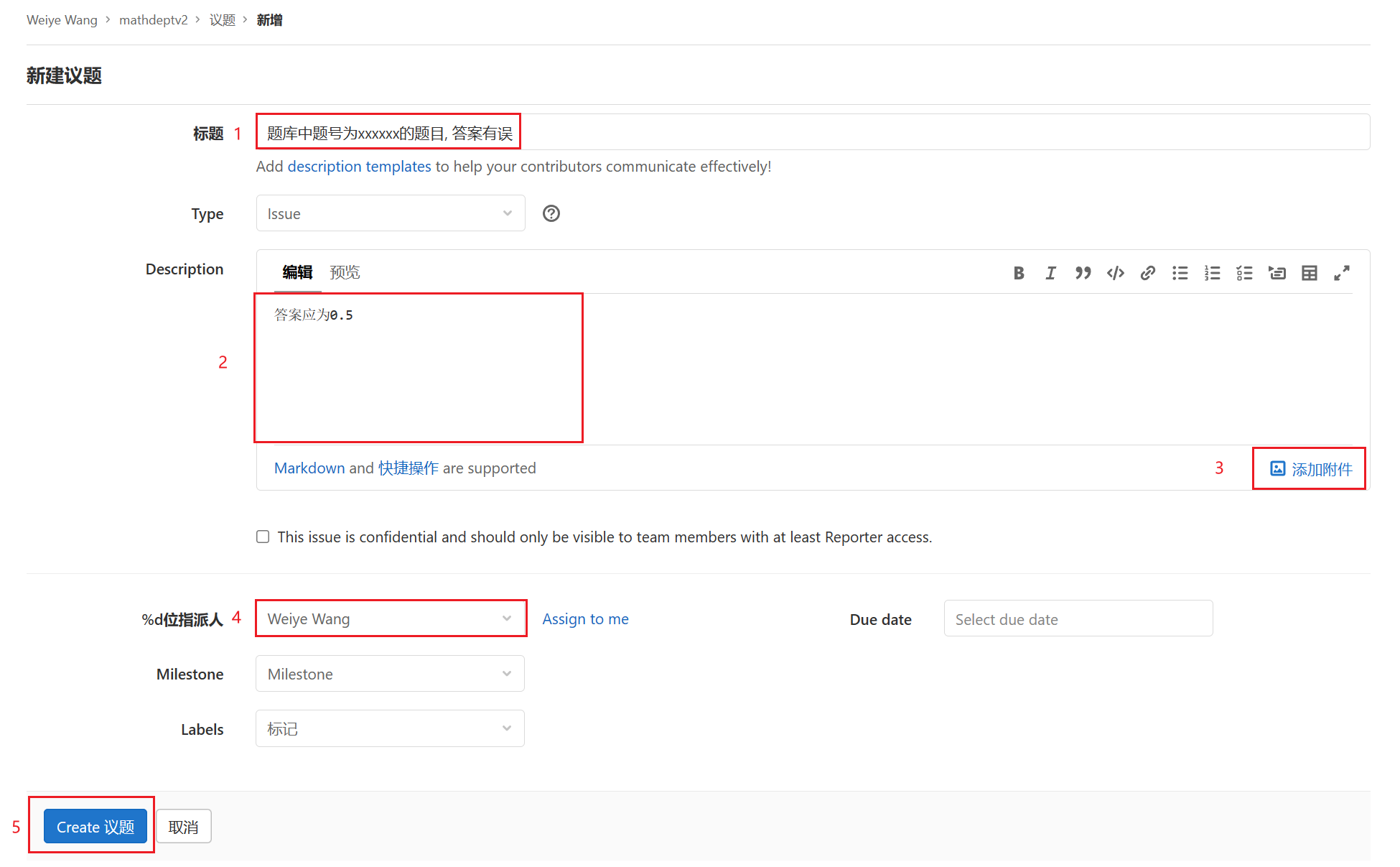
- 用简略的文字描述issue
- 详细描述issue的内容(可以使用markdown语法, 如果会markdown的话)
- 按这个按钮可以添加附件(在提供一些文件例如metadata.txt等的时候十分有用)
- 指派哪个人来跟进这个议题, 一般有同备课组的负责人和管理员等
- 前四项全填完之后, 点击
Create议题以生成这个新的issue
之后就可以在这个issue中进行对话沟通, 完成后(或者完不成但是也不想留置)有权限的成员(提出者, 指派人, 管理员等)可以关闭议题.
收录新题
对于需要合并到主题库的题目, 在收录之前请尽量和管理员协商确定起始题号, 避免不同使用者的题号出现冲突
测试的时候请先切换到远程的测试用分支, 在这个分支上进行各种操作
收录新题前, 需要准备一个能够编译通过的LaTeX文件, 正文部分是一个enumerate环境, 其中每一个\item表示一道题目. 例如:
\begin{enumerate}
\item 设$x=1$, 则$x^2$的值为\blank{50}.
\item $x=1$是$x>0$的\bracket{20}条件.
\fourch{充分非必要}{必要非充分}{充要}{既非充分又非必要}
\item 已知$f(x)=x^2+1$, 求$f(3)+f(5)$的值.
\end{enumerate}
这是一个由三道题目组成的enumerate环境(文件的其他部分可以在模板文件/讲义模板.txt中获取), 手动输入后, 可以通过面板收录到题库. 但是更多时候这样一个LaTeX文件的来源是通过mathpix识别得到的.
使用mathpix自动识别题目
mathpix是一个非常好用的数学文字和公式转换工具, 唯一的缺点是大量转换要花钱, 目前新账号的处理限额是每月10次(基本上不够用). 如果还没有注册过的话, 建议用一个邮箱注册一下. mathpix的网址是mathpix(https://mathpix.com).
下载mathpix的桌面客户端:
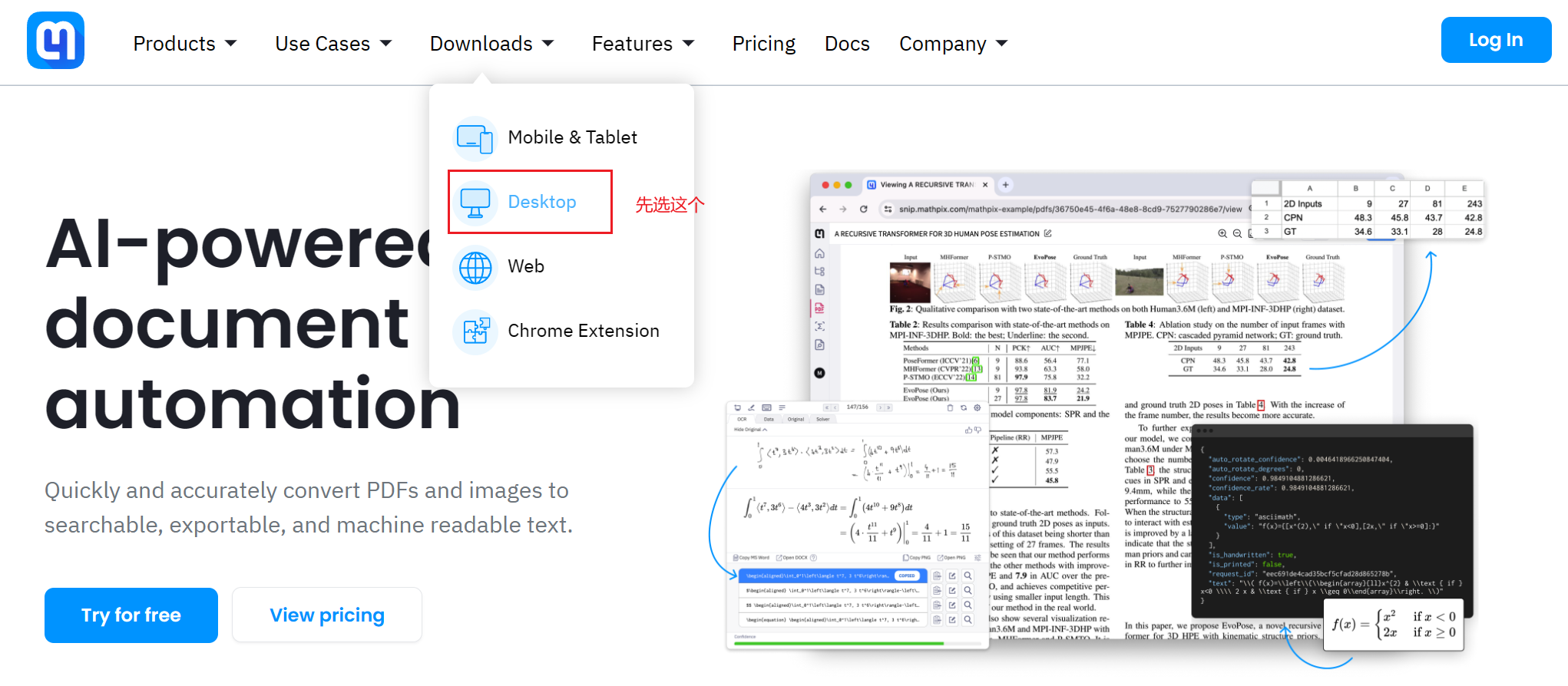
如果不想注册或者限额用完了, 以下几个账号可能可以用(限额应该会每月更新):
Nelly.Eugen@alumni.stanford.edu密码:321aA@mathpixfchavez46@student.mtsac.edu密码:Ab@789789fwhitsett@student.mtsac.edu密码:Ab@7897894552933337@student.cumtb.edu.cn密码:Ab@789789515625773@student.cumtb.edu.cn密码:Ab@789789
管理员每年会氪金一个基本上用不完的账号, 用户名是kj_wangweiye@126.com, 密码请向管理员索取.
以下以识别tutorial分支上的../文档/教学材料/待收录.png为例:
- 在资源管理器中打开这个文件(肉眼可见其中的内容).
- 启动mathpix客户端(一般会隐藏在右下角)
- 右键点击图标, 在弹出的菜单中选
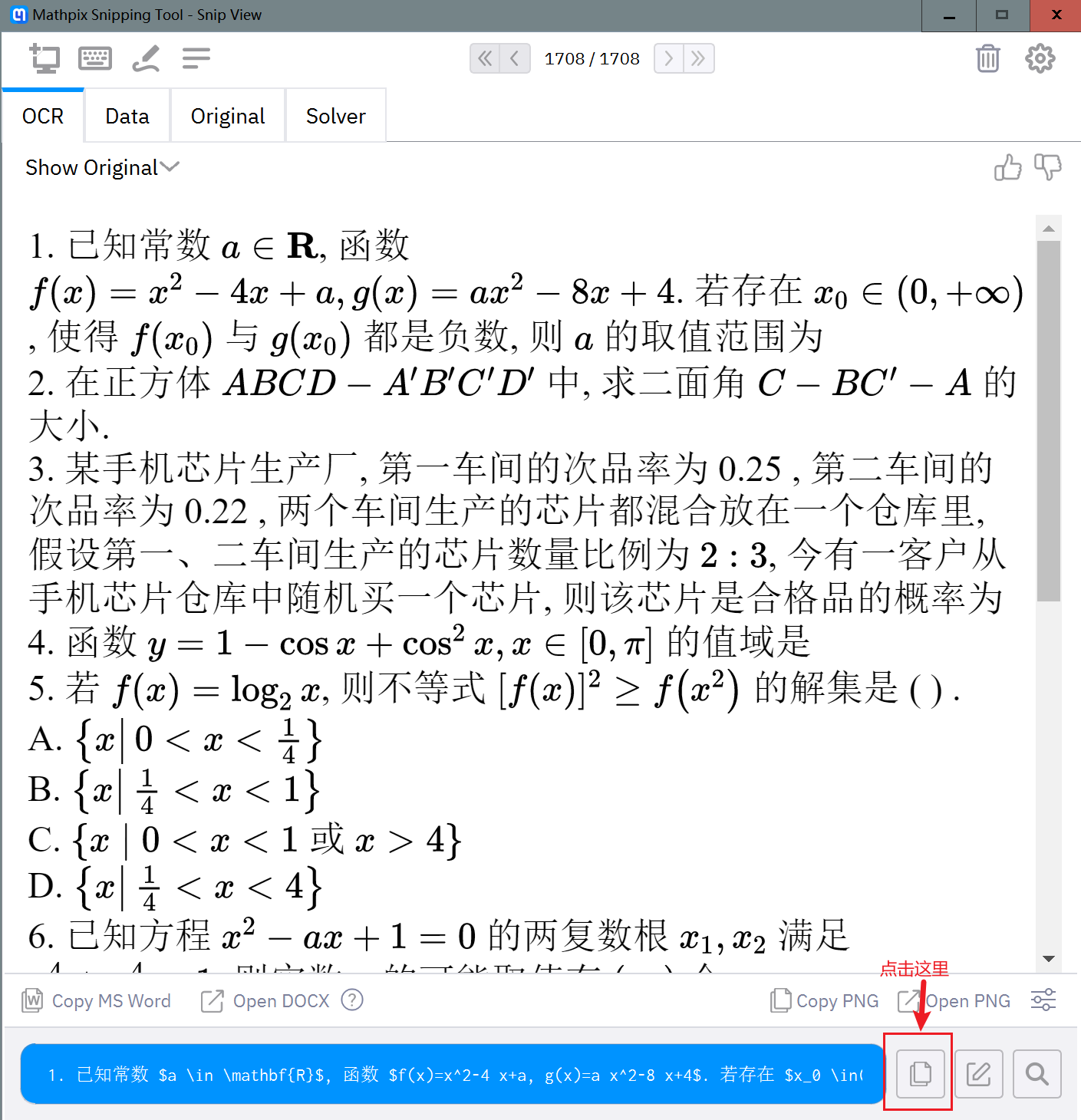
GET LATEX(后面跟着的是快捷键) - 屏幕会变成灰黑色, 并且有一个十字表示鼠标当前位置, 拖一个红色的矩形框圈住所有想要识别的文字(表会被识别, 图不会), 等待一会儿

- 在mathpix窗口中按图示方式点击, 将LaTeX代码复制到剪贴板
识别的内容复制到剪贴板之后的操作
作一些预处理, 使风格和题库中的题目的风格一致, 并确保LaTeX代码没有语法错误
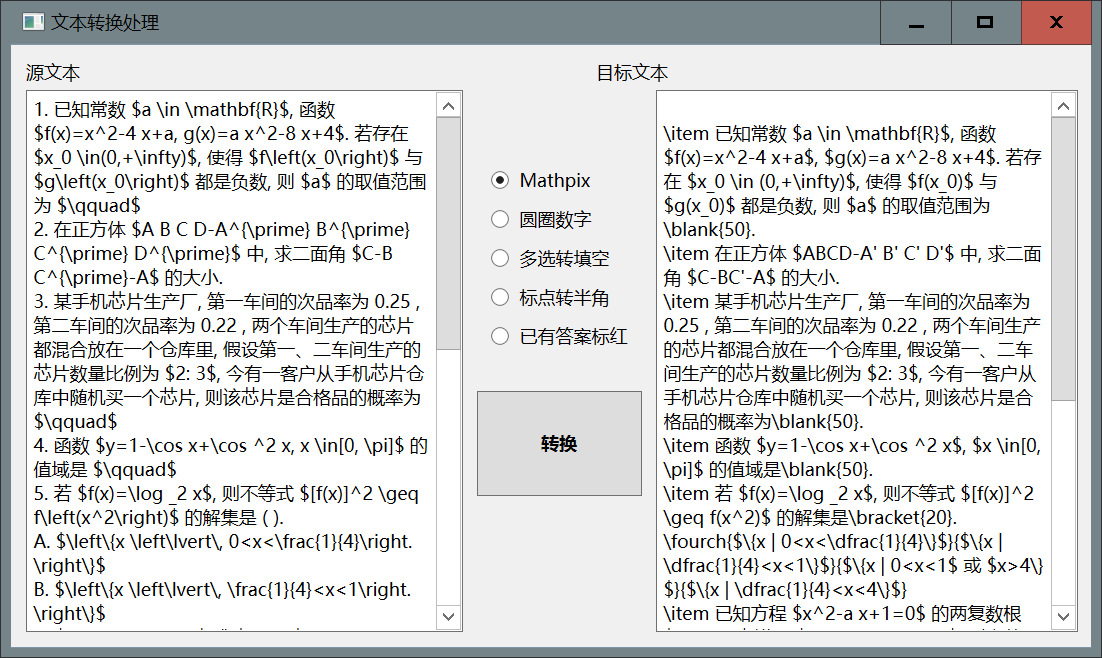
- 在面板上点击
LaTeX代码相关-文本转换处理, 选中Mathpix, 将Mathpix识别产生的代码粘贴到左侧的框中, 按运行, 右侧框中就会生成与处理之后的代码
- 在
vscode中打开模板文件/讲义模板.txt, 另存为临时文件中任意一个以.tex结尾的文件, 例如test01.tex
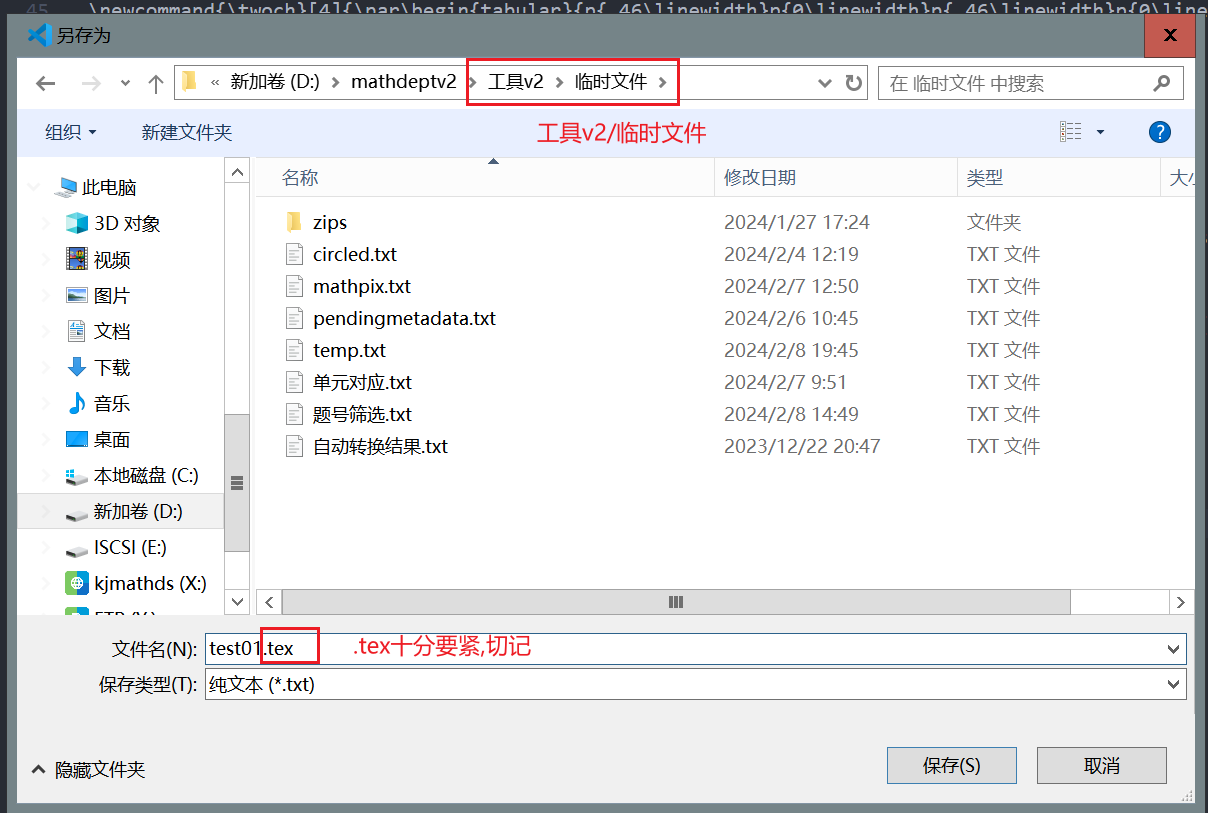
- 在该
.tex文件中将图中的<<待替换2>>替换为如下代码(粘贴后如果有代码缩进, 全选按-可取消缩进)
\begin{enumerate}
<剪贴板中的代码>
\end{enumerate}
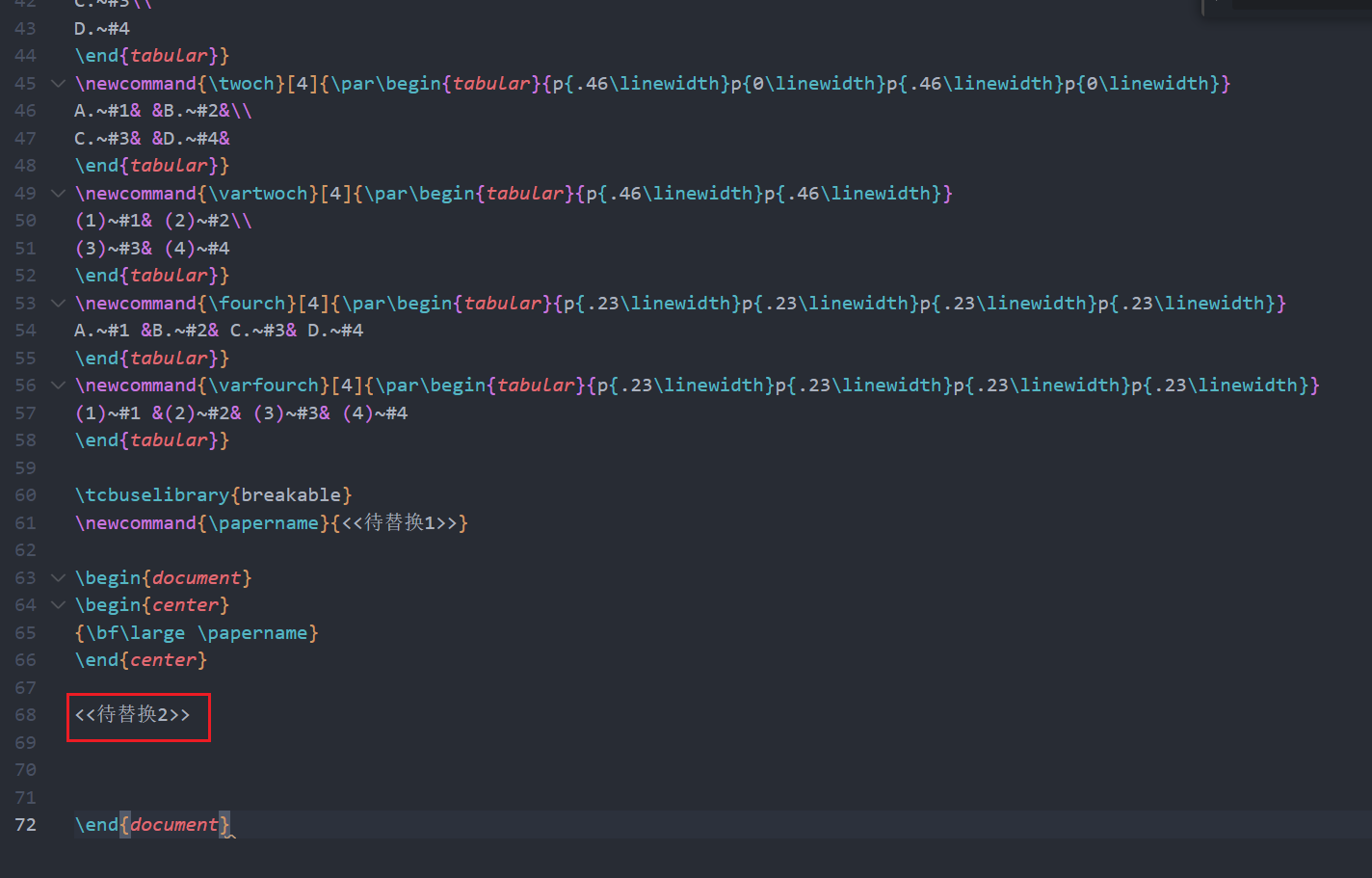
- 按
ctrl-alt-b编译, 如果下方状态栏的圈转了之后显示勾, 说明编译成功, 这时可按ctrl-alt-v查看编译结果; 如果显示红色的叉, 说明文件有问题, 需要自己或有经验的同伴帮忙检查一下 - 题目中或多或少会有一些问题, 这一步先不用修改.
- 全选
.tex文件的内容, 并复制到剪贴板.
和题库中已有的题目作比对并手动作一些标记
在导入新题到题库时, 我们一般关心每一道新题目是否和题库中已有的题目完全相同(可能描述会有细微的差别, 但不需要作较为精细的理解就能发现两道题目的含义一致, 并且题目类型[填空/选择/解答]也完全一致, 如果是选择题的话, 选项也一致), 或者明显相关联(未达到上述标准, 但是求解时所用的方法一致, 计算难度相当; 或者某一题是另一题的一部分等).
对于完全相同的题, 如果它不出现在一张规范的整卷(如一模二模卷, 高考卷等), 那事实上没有必要收录, 使用之前的题目即可; 如果它出现在一张规范的整卷中, 为了整卷的题号连续起见, 还是希望再收录一遍该题, 收录的同时作好相同的标记(same).
对于相关的题, 也希望能在收录时做好相关的标记(related).
- 在上一步的
.tex源代码全部被复制到剪贴板之后, 紧接着用面板进行新题比对, 在面板的录入菜单中选择新题比对, 立即点击运行按钮
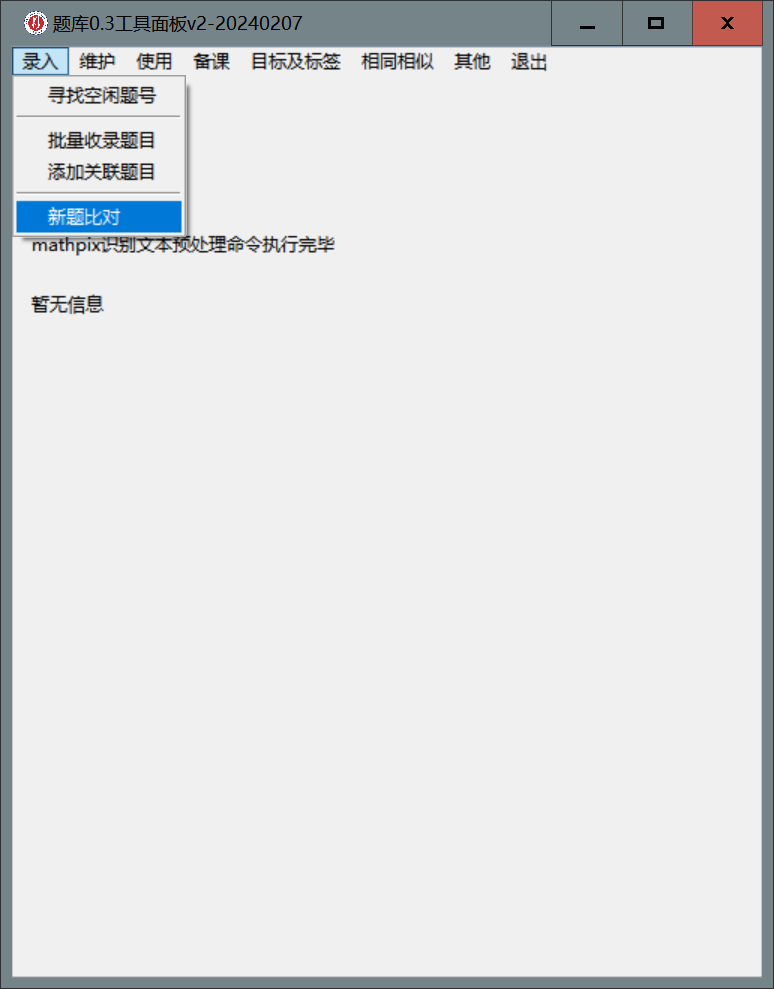
- 在
vscode中会呈现一个名为新题比对.tex的LaTeX源文件, 在该窗口内按ctrl-alt-b进行编译, 如果编译通过的话按ctrl-alt-v在右侧预览
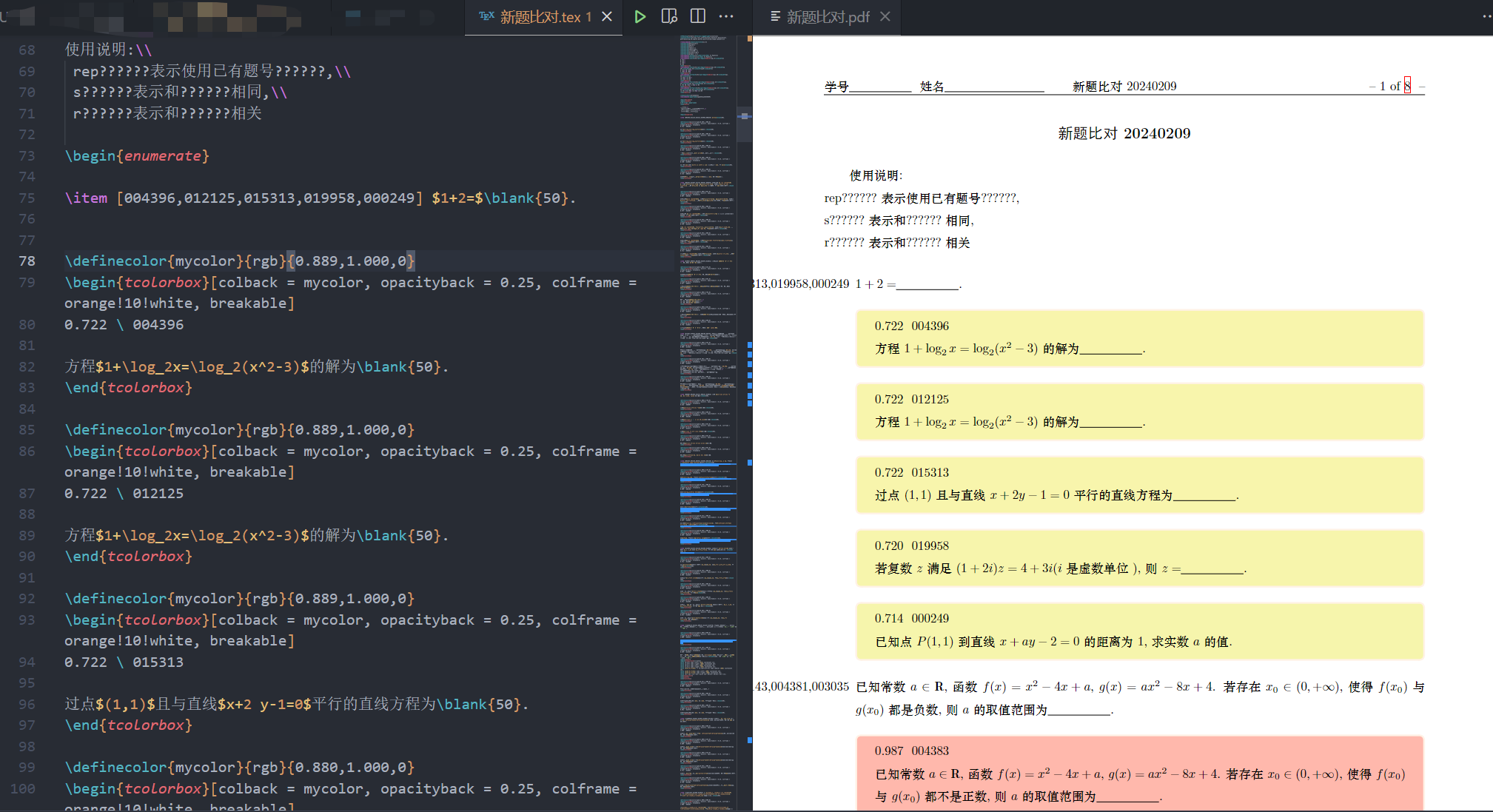
- 右侧pdf中的每一道题之后可能会有几个色块, 每一个色块表示一道字符串意义下和原题比较接近的题目(Levenshtein jaro算法), 源代码的
\item后面有一个中括号, 中括号内是色块中题目的题号. 色块越红越表示越接近. - 如果在色块中的题目和打算导入的新题是相同的, 可以用原有的题目替代, 那么在中括号中的题号前加上
rep字样(同时本题其他色块题号的标注都作为无效).

- 如果在色块中的题目和打算导入的新题是相同的, 但依然打算导入为新题, 那么在中括号中的题号前加上
s字样(同时本题其他色块题号的s,r标注依然有效), 如下图
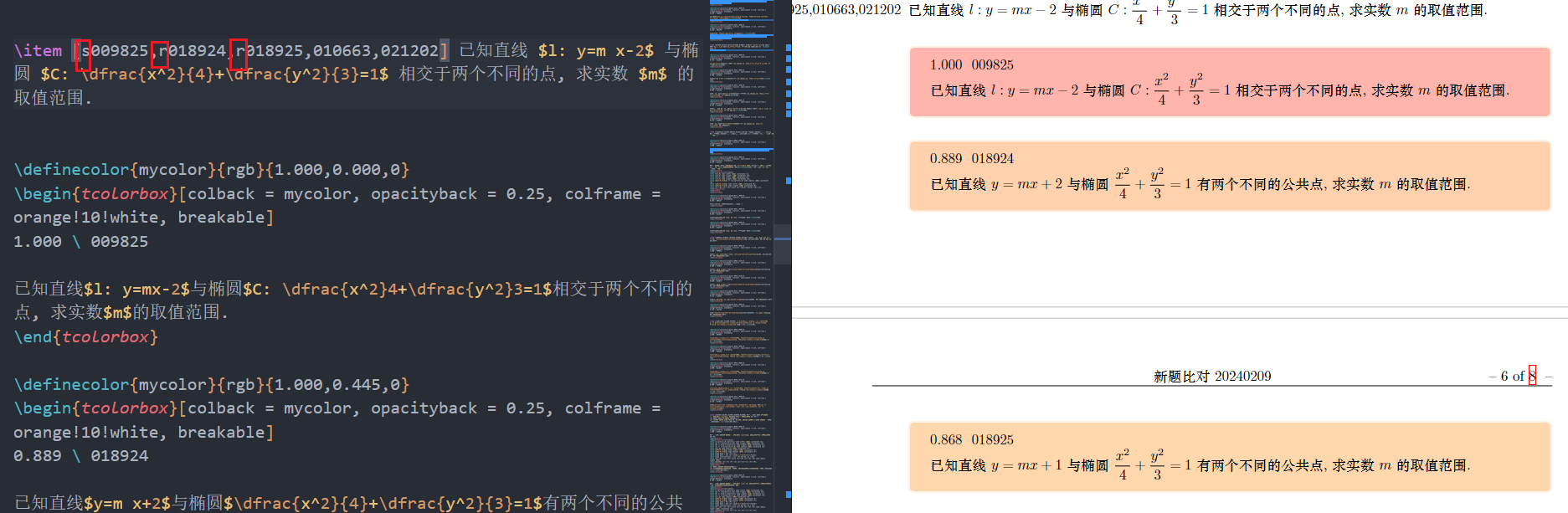
- 如果在色块中的题目和打算导入的新题是相关的, 那么在中括号中的题号前加上
r字样(同时本题其他色块题号的s,r标注依然有效), 如上图 - 在做标记时, 仔细检查欲导入的题目内容是否有明显问题, 图不会画的话在题目后方打上
缺图字样, 后续管理员会跟进处理 - 标记期间随时可以保存或编译(编译时会自动保存), 标记完成后记得
ctrl-alt-b编译, 确定没有语法错误
将标记完成的题目及相关信息一并收录到题库
- 在面板上选
录入-批量收录题目
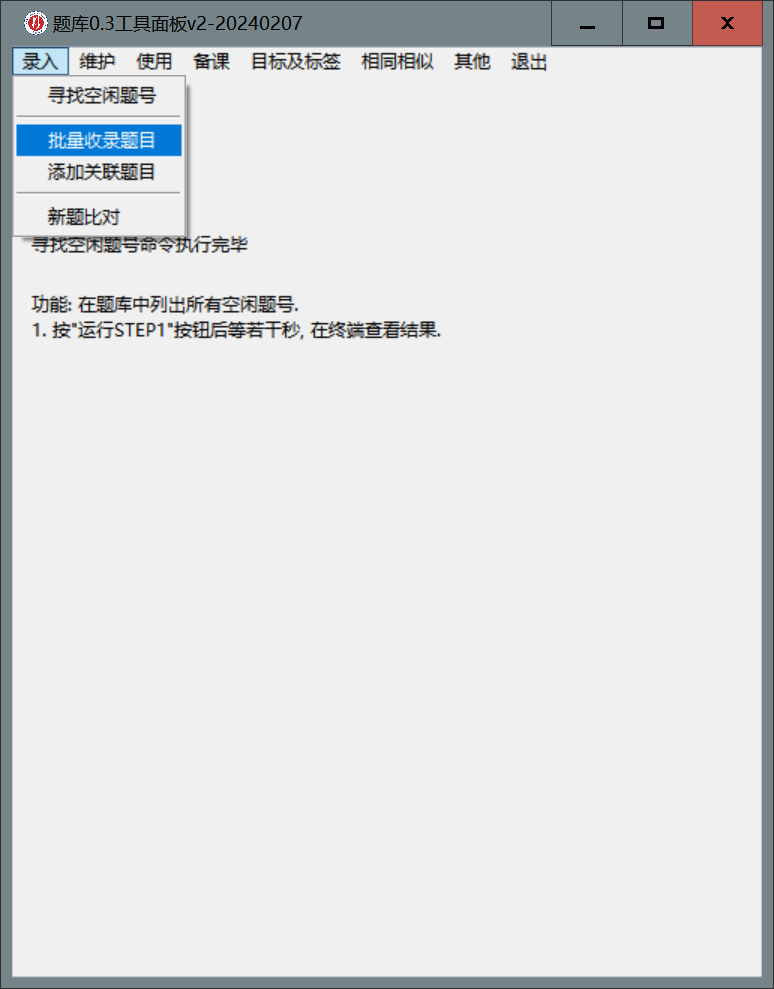
- 在
vscode的批量收录题目.py窗口中修改以下信息:
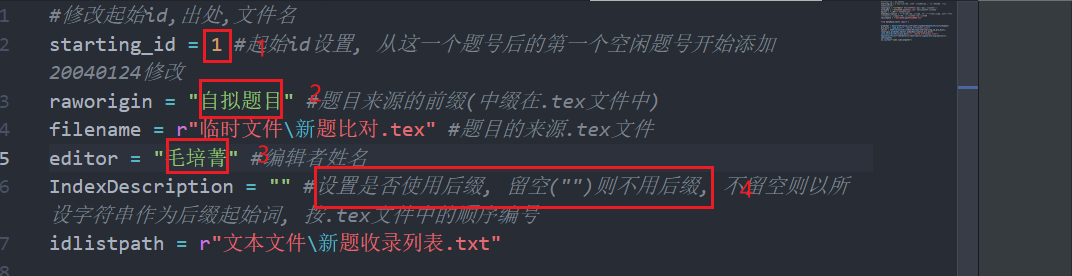
1. ``starting_id``表示起始题号(``int``类型), 如果起始题号被占用, 则会自动寻找之后的第一个空闲题号作为起始
2. ``raworigin``表示题目来源, 如果没有明确的出处建议使用``自拟题目``字符串
3. ``editor``表示收录者, 改为自己的名字
4. ``IndexDescription``是字符串, 默认留空; 如果新试题来自一张试卷, 将其改为``"试题"``, 效果是收录题目时会对题目的题号做标注, 类似``2023年上海秋季高考试题3``
- 编辑完成后保存, 关闭, 随后在面板上点击
运行按钮 - 终端会显示收录的进度, 收录完成后
vscode会打开一个名为新题收录列表.txt的窗口, 最后两行就是本次收录的信息(日期, 题号等)
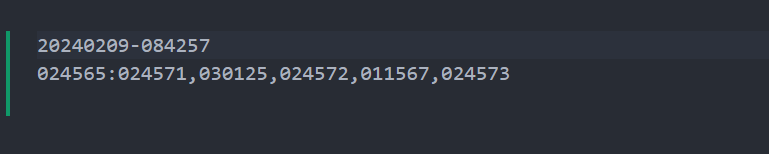
随后如果有必要, 可添加Problems.json及新题收录列表.txt至暂存区, 之后可以commit到本地的repository, 乃至push到远程的服务器.
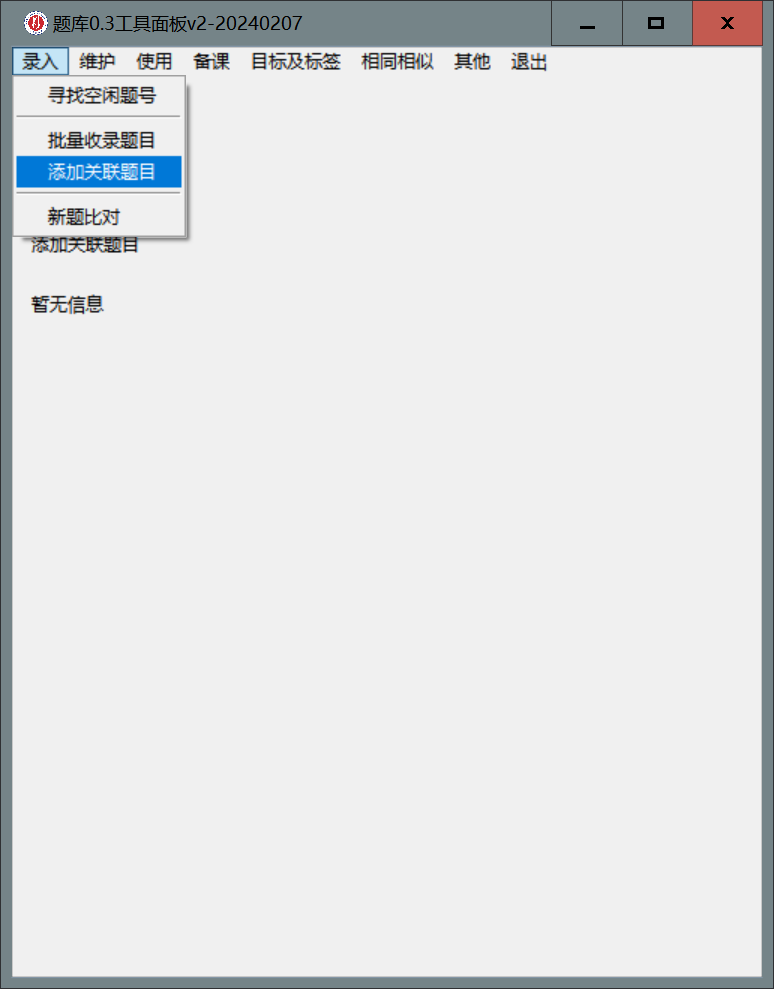
添加关联题
- 在题库中选择需要添加关联题的旧题目的题号(可用
:和,进行分隔) - 在面板上选择
录入-添加关联题目
- 对
vscode中打开的添加关联题目.py进行编辑, 一般需要修改以下三处
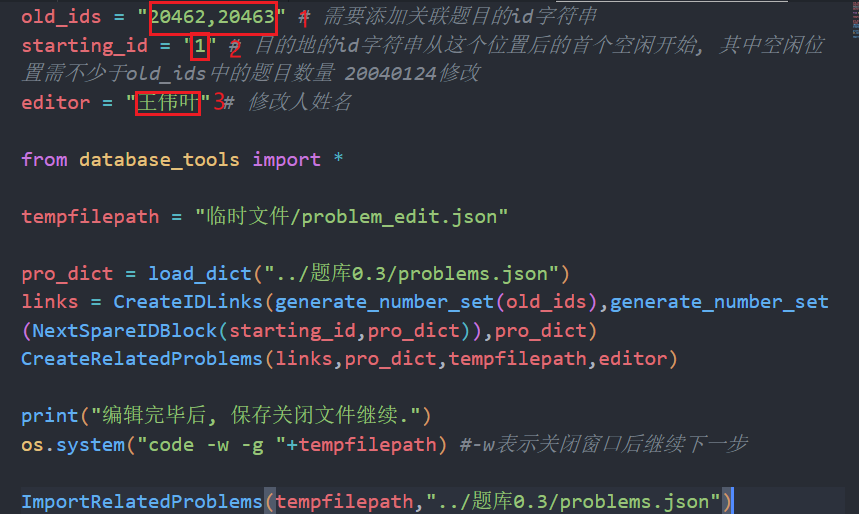
1. 修改被关联的题号(可用``:``和``,``进行分隔)
2. 新题目的起始题号(``int``类型), 如果起始题号被占用, 则会自动寻找之后的第一个空闲题号作为起始
3. 编辑者姓名
- 保存后关闭
添加关联题目.py, 在面板上点击运行 - 在
vscode中会打开一个Problems.json的文件, 目前它将旧题目的信息复制了过来, 在related字段(黄色框)中自动建立了关联.
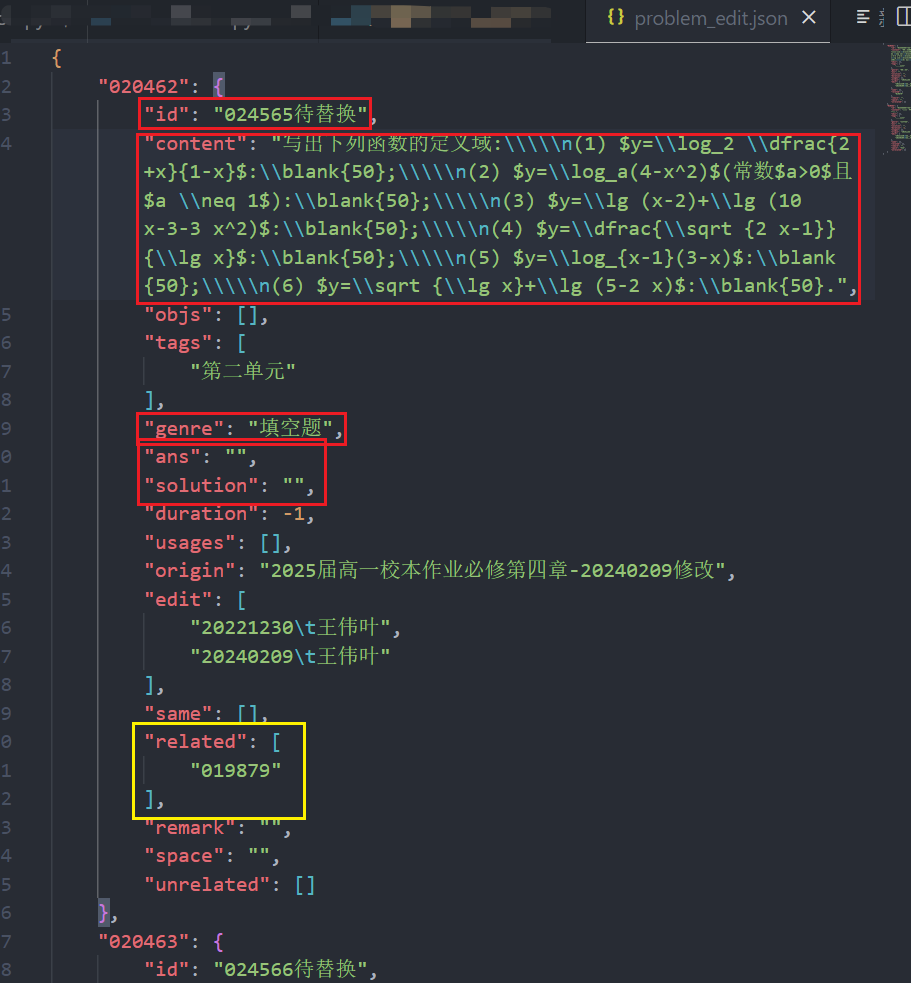
- 在编辑时(见上图),
id字段一定不要改动,content字段中保存的是raw格式的字符串, 和LaTeX代码主要的区别如下:
| raw格式 | LaTeX格式 |
|---|---|
\\ |
\ |
\n |
<换行> |
\t |
<tab> |
genre字段可能有变化(类型[填空题/选择题/解答题]可能变化了), ans和solution字段中如果有内容可能需要修改或删去(题目改变了解答和答案可能有变化)
7. 编辑完成后保存, 关闭problem_edit.json文件后, 程序会自动添加新的题目, 添加完成后会对新题目进行试编译. 如果试编译失败, 则刚才的所有编辑将全部失效(所以每次建议少添加几个关联题), 题库文件将退回原状; 如果试编译成功, 则Problems.json中的相应位置会添加对应的关联题目
随后如果有必要, 可添加Problems.json至暂存区, 之后可以commit到本地的repository, 乃至push到远程的服务器.
导入metadata(各种数据与信息, 如答案, 解答, 备注, 使用记录, 标签等)
在工具v2/文本文件目录中有一个名为metadata.txt的文件, 其一般结构如下:
ans
10235
$1$
2235
真命题
usages
021146
20231222 2025届高二11班 1.000
021147
20231222 2025届高二11班 0.952
其中ans表示答案, usages表示使用记录.
这个metadata.txt文件如果导入题库, 会
- 把第
10235题的答案用$1$覆盖, - 把第
2235题的答案用真命题覆盖, - 在
21146的usages字段中添加20231222 2025届高二11班 1.000, - 在
021147的usages字段中添加20231222 2025届高二11班 0.952.
每一个字段(如ans或usages等)及每一条记录之间都用多于一个换行符分隔(很多情况下换行之类的格式都是自动生成的), 其他metadata.txt可以接受的字段有:
content: 题目内容(str类型), 导入时将覆盖原内容objs: 课时目标(目标代码,list类型), 导入时将新增项目tags: 题目标签(list类型), 导入时将新增项目genre: 题目类型(填空题/选择题/解答题), 导入时将覆盖原内容ans: 答案(str类型), 导入时将覆盖原内容solution: 解答或提示(str类型), 导入时将覆盖原内容duration: 所需时间(单位为分钟, 暂时均赋值-1,int类型), 导入时将覆盖原内容usages: 使用记录(yyyymmdd<tab>班级代号<tab>得分率), 导入时将和之前的记录作比对, 如果确认是新的则新增项目edit: 编辑记录(list类型), 导入时将新增项目same: 相同题号(指内容和类型均相同的题目,list类型), 导入时将双向新增项目(a与b相同当且仅当b与a相同, 导入时会在两道题的记录中同时添加题号)related: 相关题号(指题目和做法都基本一致或者某一题是另一题的一部分,list类型), 导入时将双向新增项目(a与b相关当且仅当b与a相关, 导入时会在两道题的记录中同时添加题号)unrelated: 无关题号(指字符串意义上相近, 容易被自动找出, 但实际上无关的题目,list类型), 导入时将双向新增项目(a与b无关当且仅当b与a无关, 导入时会在两道题的记录中同时添加题号)remark: 备注(str类型), 导入时将新增字符串space: 题后的空间(单位一般为em, 大部分解答题默认为4em,str类型), 导入时将覆盖原内容
准备好metadata.txt文件之后, 在工具面板上按维护-批量添加字段数据
在vscode界面会打开文本文件/metadata.txt, 编辑完成后保存关闭(重要, 不关闭的话面板会处于假死状态), 面板会生成一个绿色的运行按钮, 按动按钮, 系统会自动导入数据到题库0.3/Problems.json.
随后如果有必要, 可添加Problems.json至暂存区, 之后可以commit到本地的repository, 乃至push到远程的服务器.
两种编辑题库中已有题目的方式
LaTeX方式(可编辑题目, 答案, 解答, 备注)
使用过程中, 往往会发现题库中已有的题目, 答案, 解答, 备注有错误或瑕疵, 需要修改. 这些修改不应该仅停留在讲义上(否则下次使用同一道题目还会有同样的错误), 而是应该在题库中被永久保留下来. 如果仅仅是对[题目/答案/解答/备注]的修改, 可以按LaTeX代码的方式进行操作(比直接编辑json直观), 具体方法如下:
- 在面板上选择
维护-LaTeX编辑题目答案及提示
- 在打开的
latex编辑题目答案及提示.py文件中修改一些信息
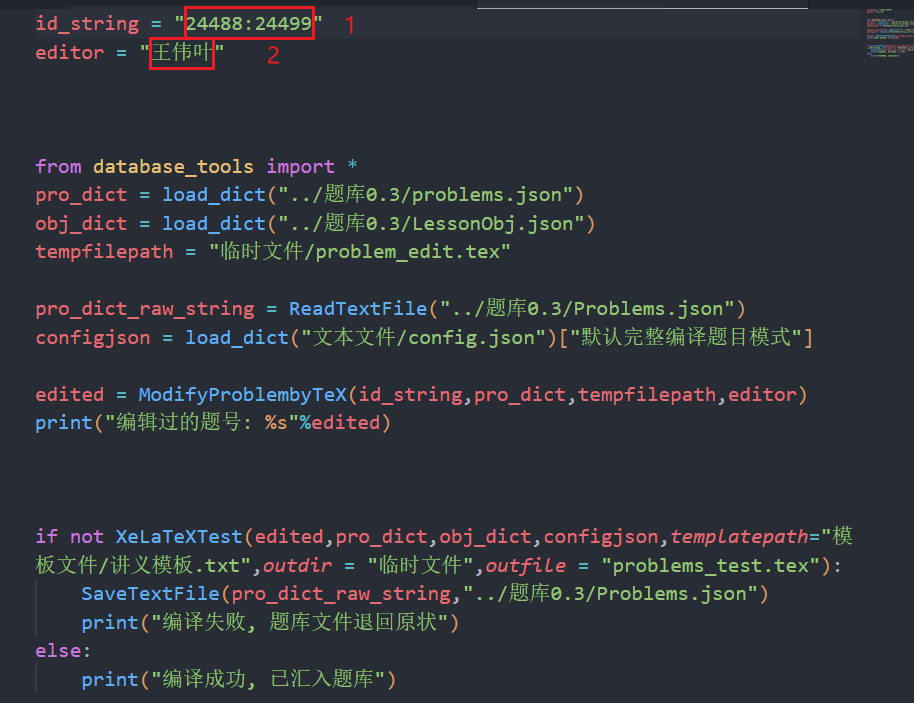
1. 要被编辑的题号(可用``:``和``,``进行分隔)
2. 编辑者
-
信息修改完成后保存, 关闭
latex编辑题目答案及提示.py, 在面板上点击运行 -
以LaTeX的方式对
vscode中新展示的problem_edit.tex进行对应的编辑, 主要的编辑在四个红色方框处, 分别是题目内容, 答案, 解答与提示, 备注. 注意在编辑时[答案/解答与提示/备注]后面冒号之后的空格和空行都不要删除.
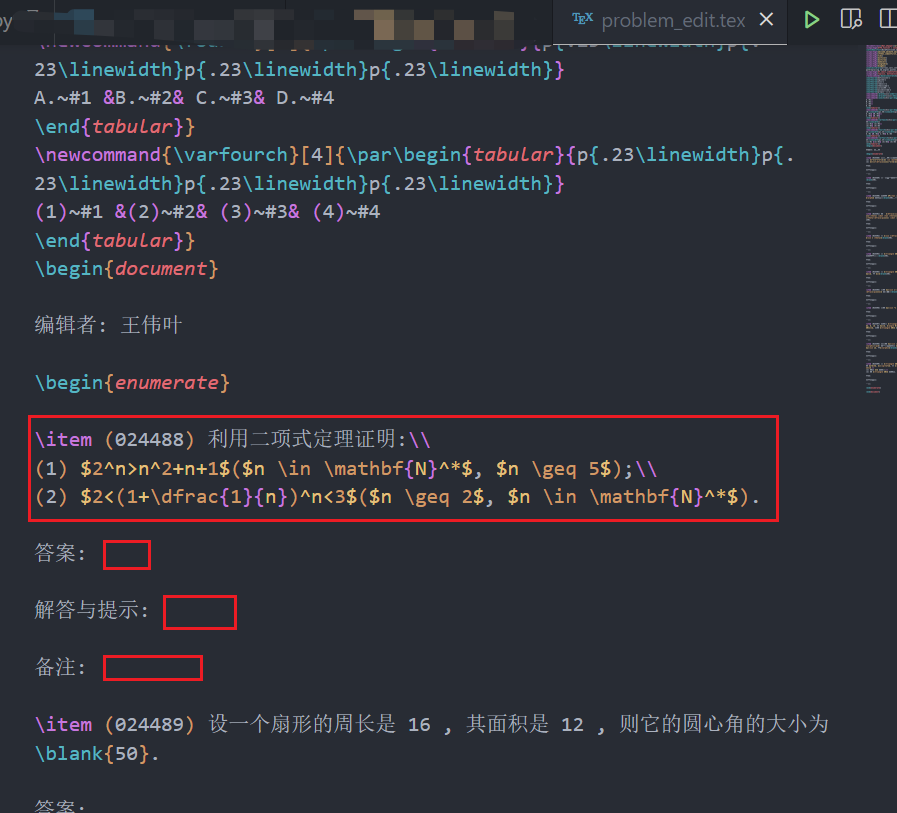
- 编辑完成后保存, 关闭, 程序会试编译编辑以后的信息. 如果试编译失败, 则刚才的所有编辑将全部失效(所以每次建议少编辑几个信息), 题库文件将退回原状; 如果试编译成功, 则
Problems.json中的相应位置会添加对应的关联题目
随后如果有必要, 可添加Problems.json至暂存区, 之后可以commit到本地的repository, 乃至push到远程的服务器.
json方式(可编辑任何信息)
使用过程中, 有时会发现题库中已有的题目的其他信息也有错误或瑕疵(例如题目类型指定错误等), 需要修改. 这些修改同样应该在题库中被永久保留下来. 它们都可以按json代码的方式进行修改, 具体方法如下:
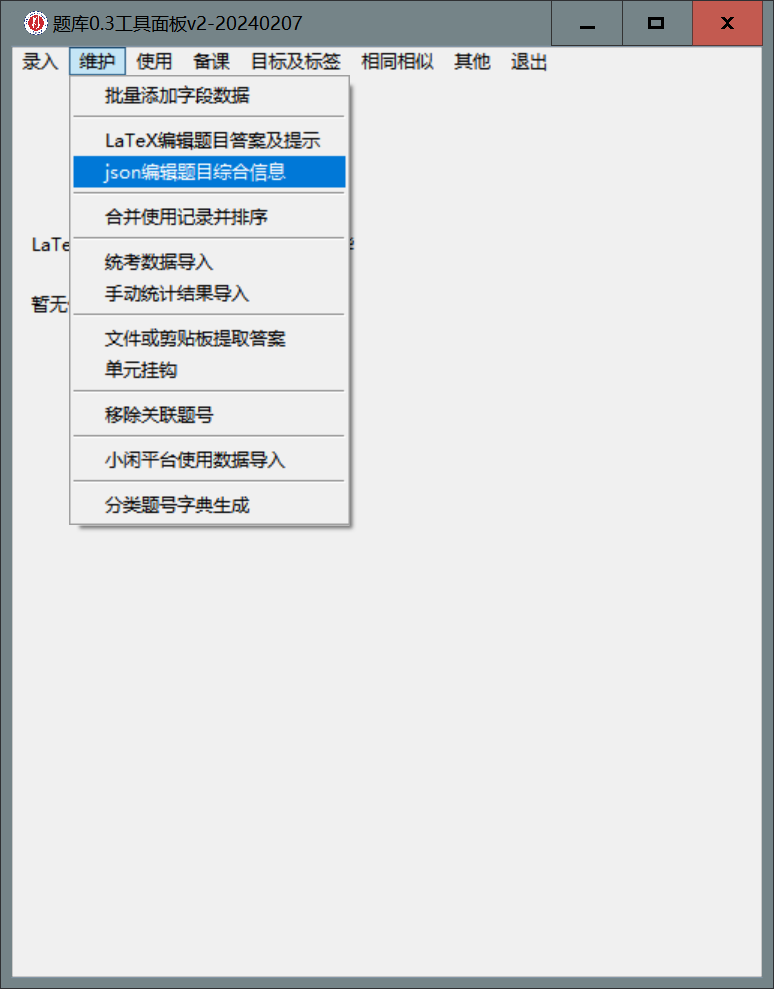
- 在面板上选择
维护-json编辑题目综合信息
- 在打开的
json编辑题目综合信息.py文件中修改一些信息
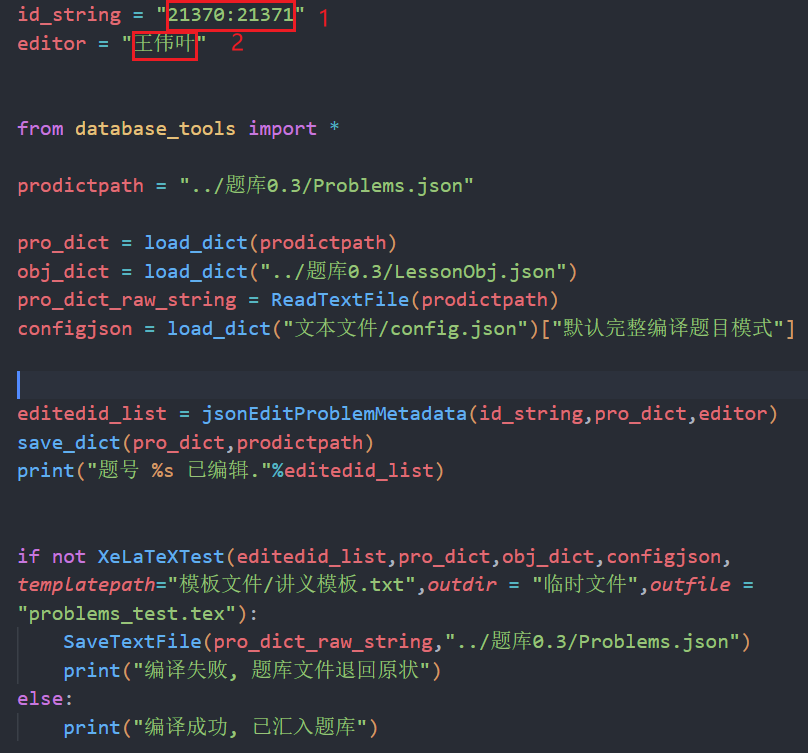
1. 要被编辑的题号(可用``:``和``,``进行分隔)
2. 编辑者
- 信息修改完成后保存, 关闭
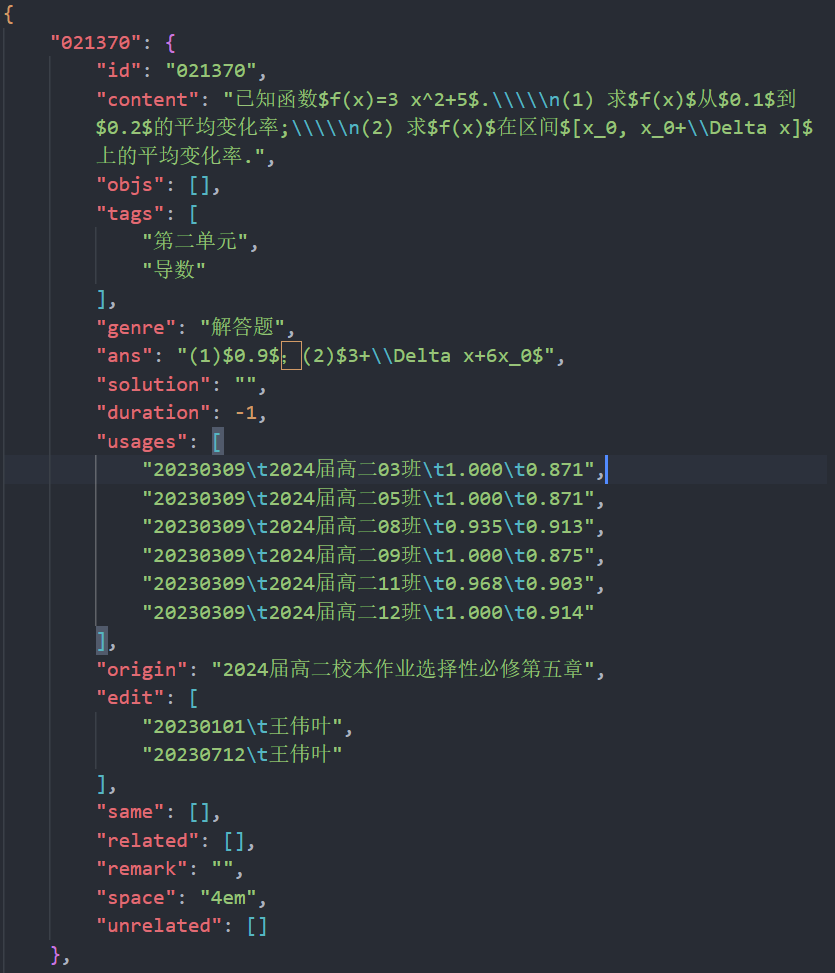
json编辑题目综合信息.py, 在面板上点击运行 - 在
vscode对新展示的problem_edit.json进行对应的编辑(例如下图中的全角分号改为;[半角分号空格]). 编辑时字段名, 含义, 类型参考导入metadata部分的说明
- 编辑完成后保存, 关闭, 程序会试编译编辑以后的信息. 如果试编译失败, 则刚才的所有编辑将全部失效(所以每次建议少编辑几个信息), 题库文件将退回原状; 如果试编译成功, 则
Problems.json中的相应位置会添加对应的关联题目
随后如果有必要, 可添加Problems.json至暂存区, 之后可以commit到本地的repository, 乃至push到远程的服务器.
根据特定特征筛选题号(已更新为Qt面板)
案例1 筛选内容中同时含有最小值(或最大值) 函数 ^3(3次方)字样的题目
- 在面板上选择
使用-关键字筛选题号, 点击绿色的运行按钮.
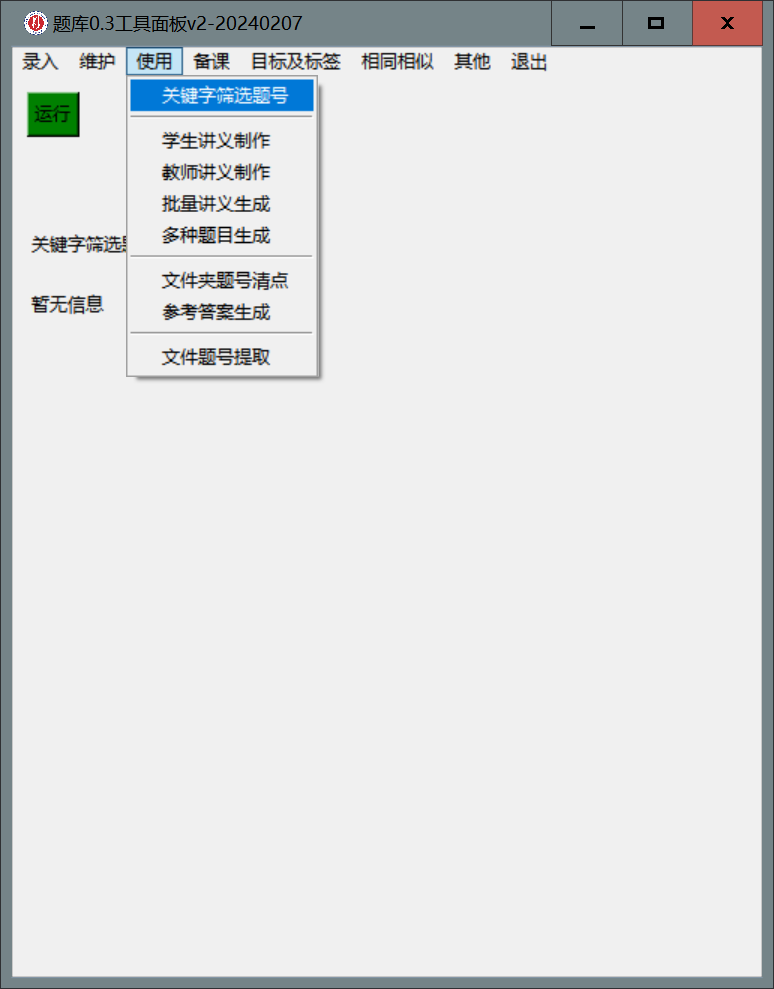
- 在弹出的面板上右上方的文本框中输入
最大值, 最小值(,表示至少有一个)后点击内容, 随后点击左下方的运行, 液晶数字会急剧减小, 表示符合要求的题目数量减少了.
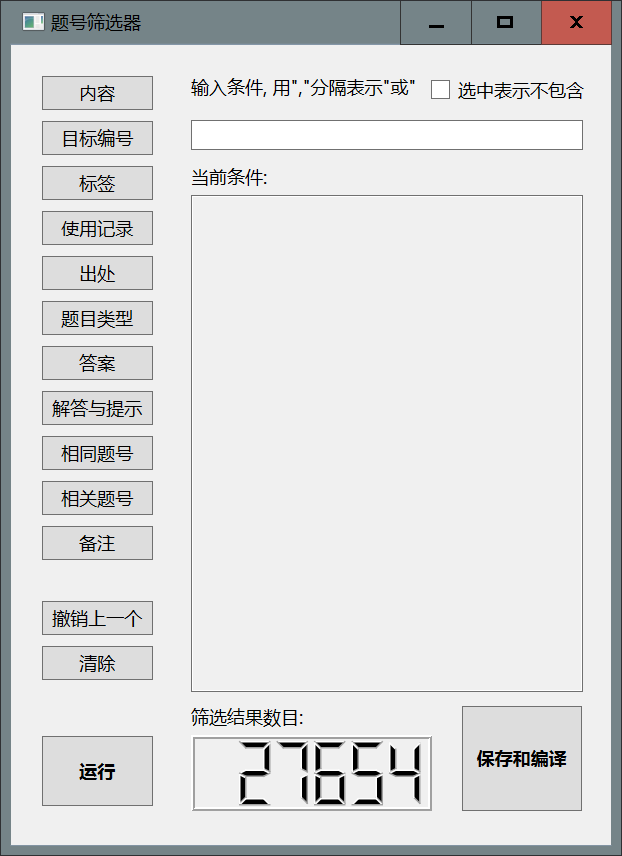
- 删去文本框的内容, 在文本框中输入
函数, 点击内容, 随后点击左下方的运行, 题目数量继续减少.
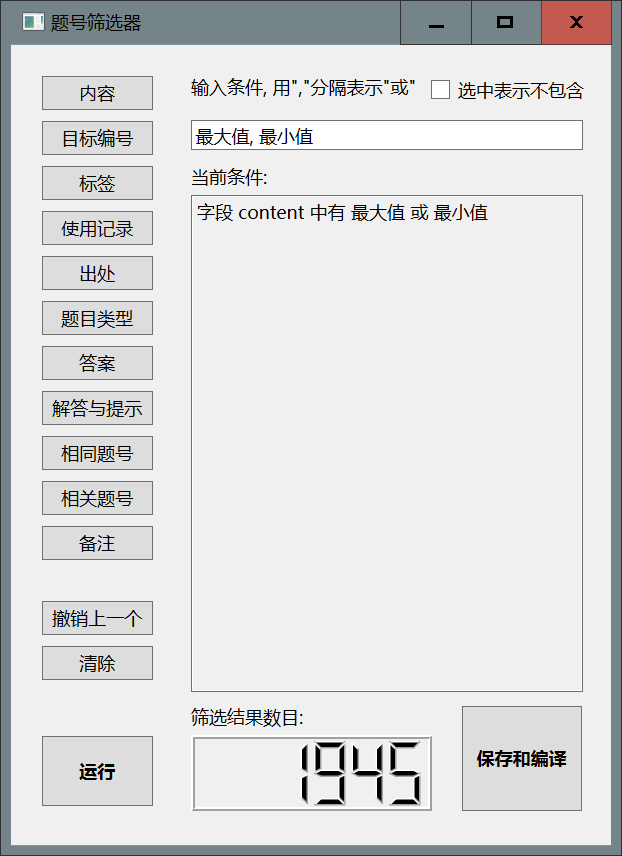
- 删去文本框的内容, 在文本框中输入
\^3, 点击内容, 随后点击左下方的运行, 题目数量继续减少.
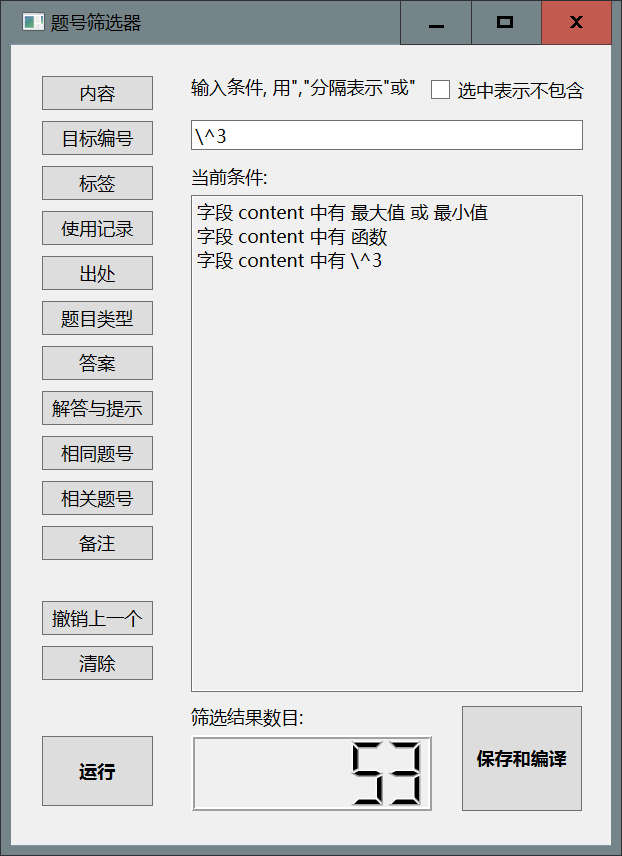
- 点击
运行按钮, 再点击保存和编译按钮(vscode的终端已经开始有动静了), 一小段时间之后, 可以在临时文件目录找到筛选题目编译.pdf文件, 这就是符合要求的所有题目. 题号在临时文件目录下的题目筛选.txt中.
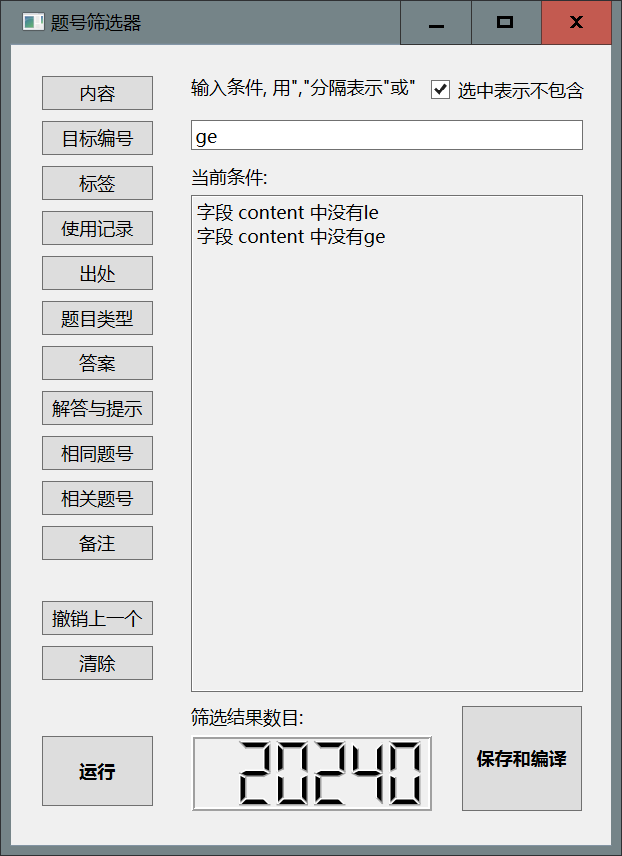
案例2 筛选2026届有使用记录, 题目中没有大于等于号, 也没有小于等于号, 并且标签含第一单元(预备知识)的题目
-
在面板上选择
使用-关键字筛选题号后, 点击运行键. -
在选中
选中表示不包含左侧的方框的同时, 在文本框中输入le, 点击内容, 再输入ge, 点击内容.
-
在未选中
选中表示不包含左侧的方框的同时, 在文本框中输入第一单元, 点击标签, 在文本框总输入2026届, 点击使用记录 -
点击
运行 -
再点击
保存和编译按钮(vscode的终端已经开始有动静了), 一小段时间之后, 可以在临时文件目录找到筛选题目编译.pdf文件, 这就是符合要求的所有题目. 题号在临时文件目录下的题目筛选.txt中.
案例3 筛选2024届的使用记录中出现过0.1??或0.2??的所有题目
-
在面板上选择
使用-关键字筛选题号后, 点击运行键. -
在未选中
选中表示不包含左侧的方框的同时, 在文本框中输入2024届.*0\.[12]\d{2}后点击使用记录 -
点击
运行 -
再点击
保存和编译按钮(vscode的终端已经开始有动静了), 一小段时间之后, 可以在临时文件目录找到筛选题目编译.pdf文件, 这就是符合要求的所有题目. 题号在临时文件目录下的题目筛选.txt中.
案例3 筛选答案为$2$(LaTeX公式环境下的2)的所有题目
-
在面板上选择
使用-关键字筛选题号后, 点击运行键. -
在未选中
选中表示不包含左侧的方框的同时, 在文本框中输入^\$2\$$后点击答案 -
点击
运行 -
再点击
保存和编译按钮(vscode的终端已经开始有动静了), 一小段时间之后, 可以在临时文件目录找到筛选题目编译.pdf文件, 这就是符合要求的所有题目. 题号在临时文件目录下的题目筛选.txt中.
根据题号表达式(可含:或,的字符串)生成讲义
一个很常见的需求是根据题号字符串(常来自于关键字筛选题号功能)生成一个包含题目以及相关信息的pdf文件. 方法如下:
- 准备好一个题号字符串(例如来自于
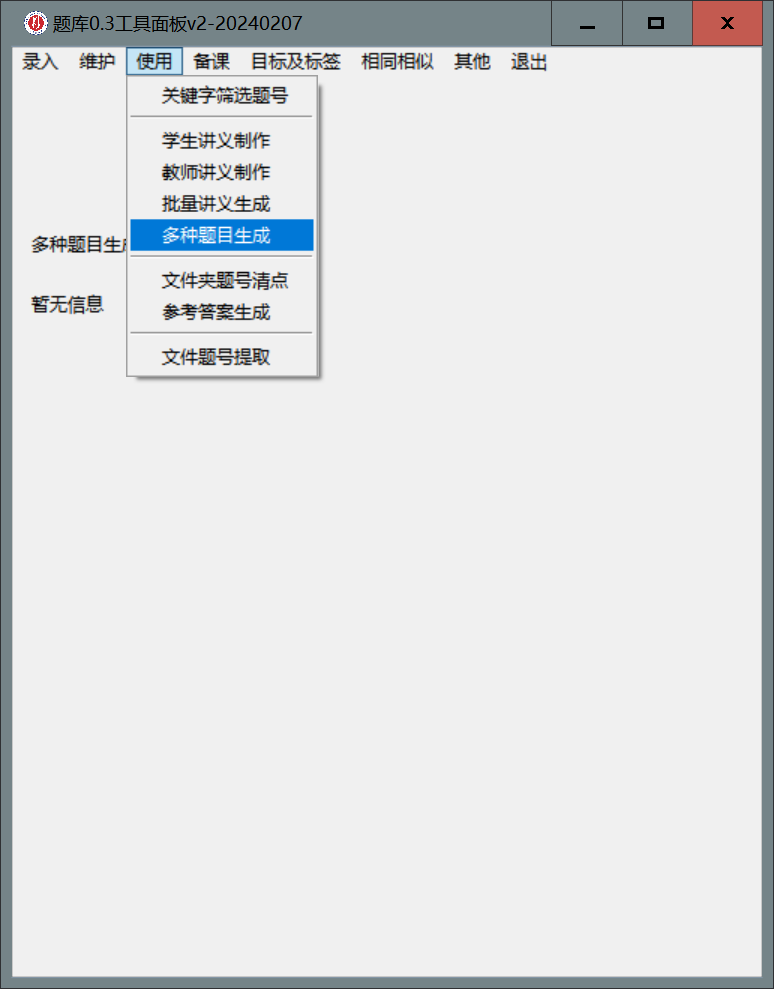
关键字筛选题号或者直接手搓一个比如12300:12305,20100:20103) - 在面板上选择
使用-多种题目生成
- 在
vscode自动打开的config.json文件的"多种题目生成.py"部分进行编辑, 一个案例如图:

- 编辑完成后保存, 关闭
config.json, 点击运行, 稍等一会儿之后, 就能在临时文件文件夹中根据文件名或者修改时间找到按照要求编译的pdf文件了
系列讲义生成
除了根据自己的需求生成讲义之外, 用题库生成讲义的另一个主要方式是根据题库中现有的讲义结构生成一张或多张讲义. 从2023学年第2学期开始(部分年级从第1学期开始), 讲义的题号数据都被规范地保存在了我们的题库项目中. 以下是生成讲义的方法:
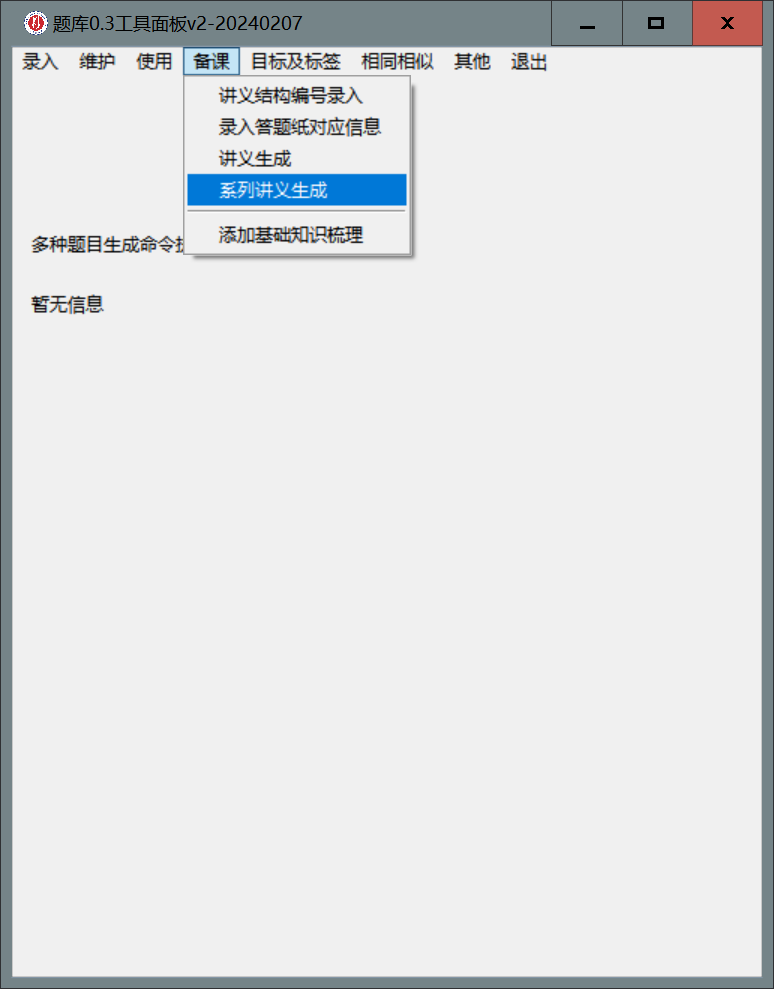
- 在面板上选择
备课-系列讲义生成
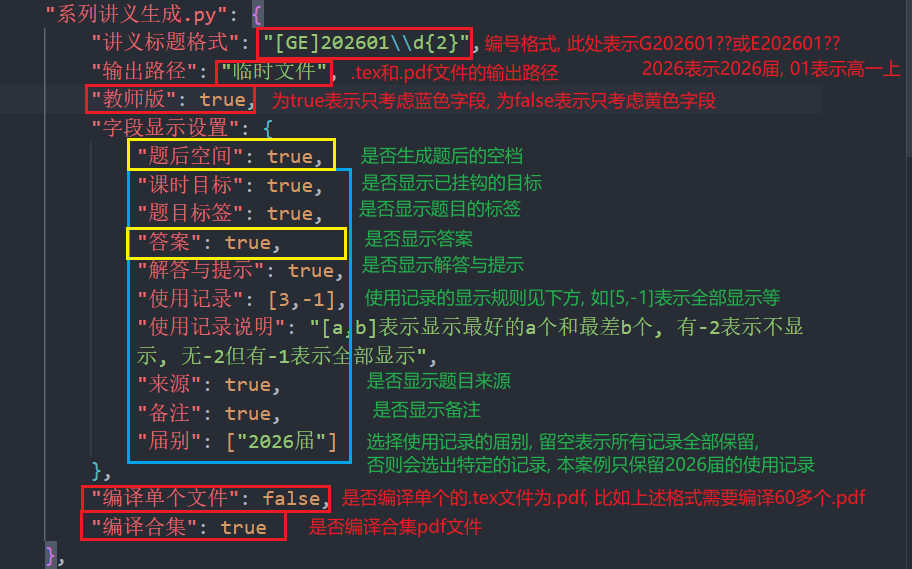
- 在
vscode自动打开的config.json文件的"系列讲义生成.py"部分进行编辑, 一个案例如图:
-
编辑完成后保存, 关闭
config.json, 点击运行, 稍等一会儿之后, 就能在指定的文件夹中根据文件名或者修改时间找到.tex文件(有单个的, 也有合集)和按照要求编译的.pdf文件了(根据设定, 合集文件命名为合集<yyyymmdd>.pdf), 我们的案例将编译出一个715页的pdf文件 -
其中单个的.tex文件都是可以打开编译或编辑的
从LaTeX源文件中提取答案
在目前的版本下, 自动编译的pdf中, 已经录入过的答案都用红色\textcolor{red}{xxx}表示, "暂无答案"字样均用蓝色\textcolor{blue}{暂无答案}表示.
建议把要添加答案的题目自动生成一个.tex文件(通过"根据题号表达式生成讲义"功能或"系列讲义生成"功能), 随后对.tex文件在vscode(个人)或overleaf(团队)上录入答案, 也就是把大括号中的"暂无答案"字样改为答案即可. 录入过程及录入后多编译查看效果和查看错误.
无论答案是否已经录入完毕, 都可以通过面板上的维护-文件或剪贴板提取答案功能提取文件中(或剪贴板上)的LaTeX代码中的答案.
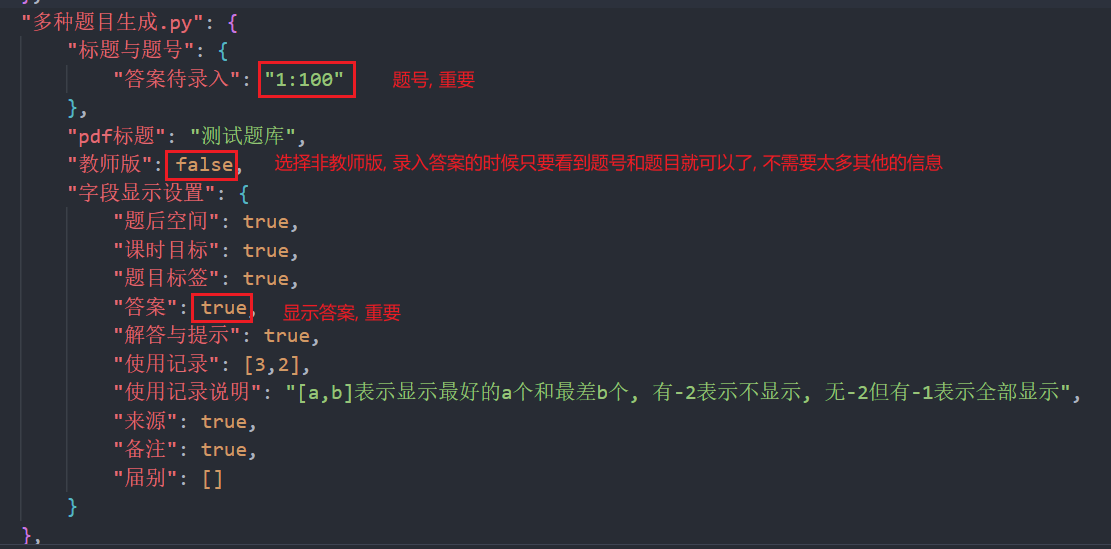
例如为题号为1到100的还没有编写答案的题目编写答案的过程如下:
- 用题号为1-100的题目生成一个.tex文件(
使用-多种题目生成),config.json文件中的重要改变如图, 点运行, 稍候一会儿
- 在
临时文件中找到刚生成的.tex文件, 双击后在vscode中打开,ctrl-alt-b编译,ctrl-alt-v查看编译结果
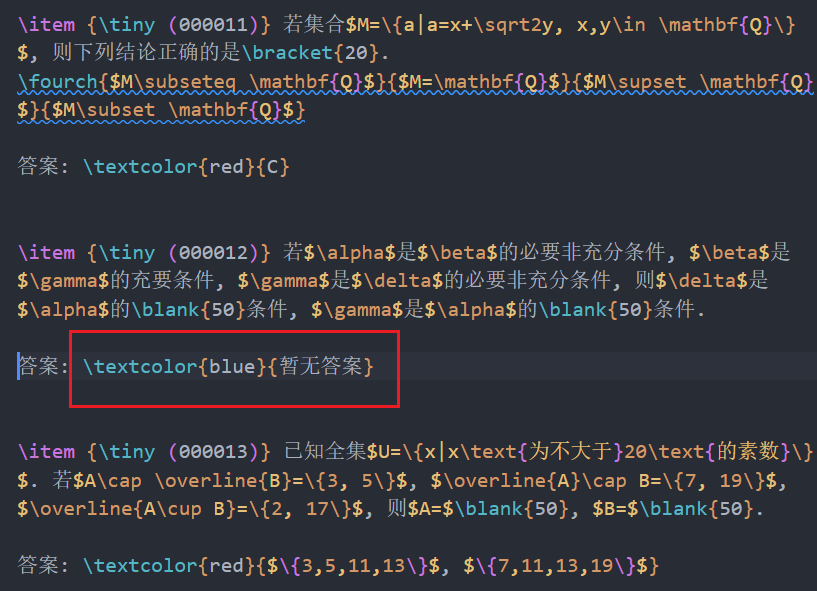

- 修订蓝色的答案, 如果有红色的答案想要修订, 也把前面的red改为blue
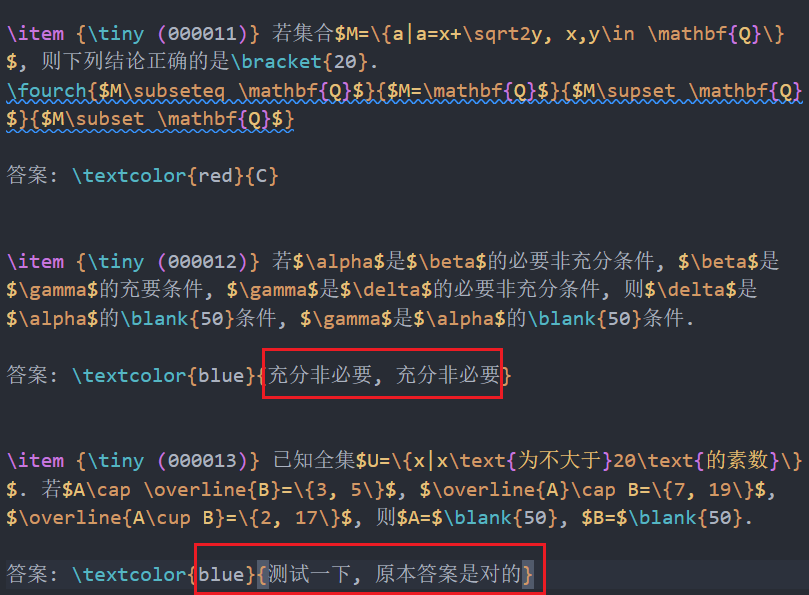

- 完成修订后全选LaTeX代码, 复制到剪贴板. 在面板上选
维护--文件或剪贴板提取答案
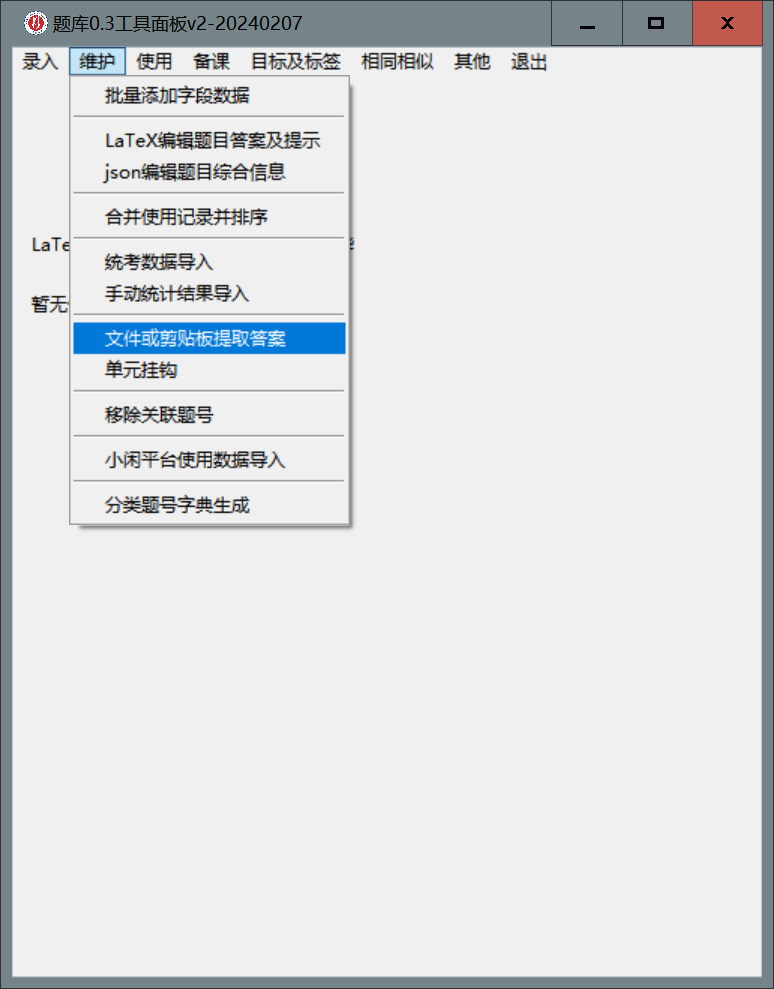
- 在随后
vscode窗口的config.json中文件或剪贴板提取答案.py部分的来自剪贴板:后填入true(如果填入false的话, 需要修改下一行的文件地址为录入过答案的LaTeX文件的地址).前缀一行不改动.
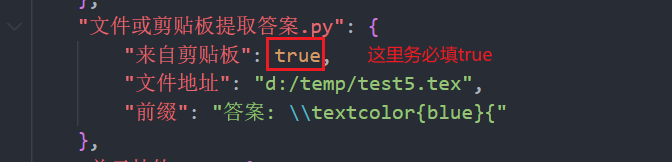
- 保存
config.json并关闭, 在面板上点击运行. 题号与答案的对应就已经在文本文件/metadata.txt中了

随后可以使用面板上的维护-批量添加字段数据功能将答案正式导入数据库. 之后如果有必要, 可添加Problems.json至暂存区, 之后可以commit到本地的repository, 乃至push到远程的服务器.
题目和单元挂钩
因为题库不断有新题被收录, 所以把新题与1-9的九个单元挂钩是一项定期要做的工作, 好在现在这个工作的流程已经变得比较简单了. 我们编写了程序, 可以根据字符串的相似程度自动地给一部分题目挂钩单元(当然, 准确度还不是最高, 需要人工校验一下). 对于那些无法找到足够相似题目的新题, 需要手动输入一下单元编号.
目前的单元对应方式在../题库0.3/UnitNames.json中, 是这样的
"1": "预备知识",
"2": "函数",
"3": "三角与三角函数",
"4": "数列",
"5": "平面向量与复数",
"6": "立体几何",
"7": "解析几何",
"8": "计数原理与概率",
"9": "统计"
需要指出的是, 和三角函数的导数有关的内容一般归入第2单元, 和空间向量有关的内容一般归入第6单元.
对新题进行单元挂钩一般需要以下两步(为了防止merge conflicts, 第二步一般由管理员完成).
生成"未挂钩单元题目"的LaTeX源文件、pdf文件与数据文件(临时文件/单元对应.txt)
- 在面板上选择
维护-单元挂钩选项
- 在
vscode中对自动打开的config.json文件的单元挂钩.py部分进行编辑. 第一个红色框处输入1, 第二个红色框留空(表示仅对新题进行处理)
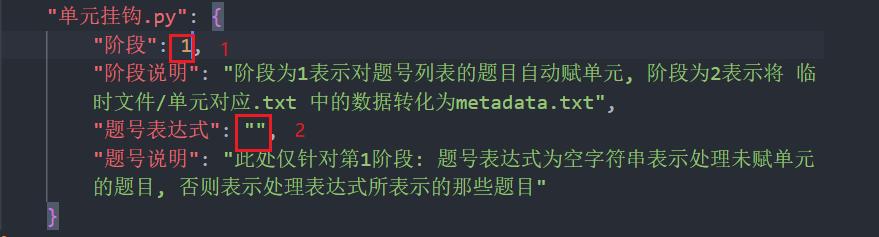
- 编辑完成后保存并关闭
config.json文件, 在面板上点击运行按钮. 会在临时文件目录中生成一个待检查单元.pdf文件, 同时在相同的目录下生成一个单元对应.txt文件. 这两个文件都会自动打开, 而且其中的信息是对应的.

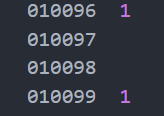
- 逐一检查自动对应的单元是否正确(如果不正确的话, 只需在.txt文件中修改), 并将未自动对应的题号的单元在.txt文件中录入. 单元号支持
253这种对应多个单元的语法.
事实上这里更便捷的方式是把待检查单元.pdf文件导入到pad进行手写修改和关联, 修改和关联完之后再把数据逐一填入单元对应.txt文件. 一般熟练的话半小时可完成500题以上的关联工作.
- 工作完成后
待检查单元.pdf就已经没有用了,单元对应.txt文件非常重要, 请妥善保存.
根据数据文件(临时文件/单元对应.txt)生成metadata.txt
-
将
单元对应.txt放置在临时文件目录下(如果没有移动过的话, 它本来就在那儿) -
在面板上选择
维护-单元挂钩选项
- 在
vscode中对自动打开的config.json文件的单元挂钩.py部分进行编辑. 红色框处输入2.
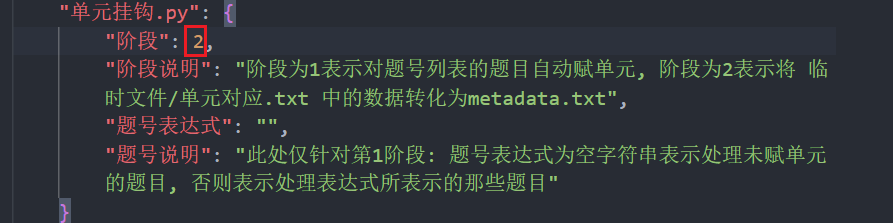
- 编辑完成后保存并关闭
config.json文件, 在面板上点击运行按钮. 程序会将单元对应.txt中已经对应单元的题号(单元号后面没有数字的会自动放弃)中的单元信息保存到文本文件/metadata.txt中并打开该文件. 建议将该文件用提交issue的方式发给管理员, 管理员可以用维护-批量添加字段数据功能将信息导入到题库0.3/Problems.json数据库, 如果仅仅是为了测试, 可以自行操作后在git面板中观察Problems.json文件在导入前后的变化
录入讲义结构与内容
讲义首字母的通用规则(2023学年第2学期起实施)
- E: 正式测验卷与考试卷
- I: 非正式的小测验
- W: 周末卷
- G: 高一高二的学案
- J: 高三的复习讲义
- F: 高三的赋能卷
- V: 假期作业
录入新的讲义种类的结构(备课组之前未使用过的首字母)
TBD(先看视频)
录入新的讲义的题号ID等内容
TBD(先看视频)
对小闲平台的答题纸与数据库进行对应
对应的目的是能更方便地收录使用信息
TBD(先看视频)
小闲平台使用数据导入
如果在备课组数据库中已经做了小闲平台答题纸与题号, 分数的对应, 可以使用面板方便地导入使用记录到数据库(建议自行生成metadata.txt后用issue的方式提交给管理员, 由管理员导入, 避免merge conflict)
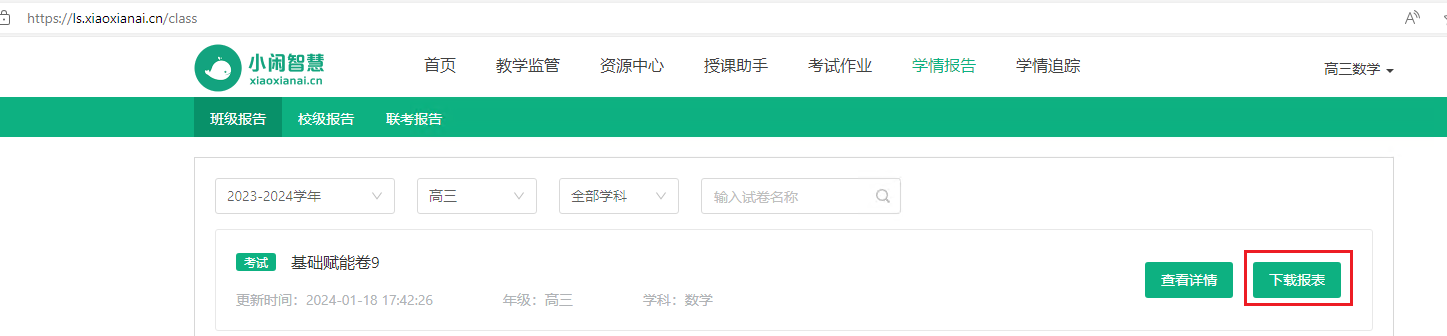
- 在小闲平台
ls.xiaoxianzi.cn用浏览器登录(注意不要用客户端), 在想要处理的作业或考试处点击下载报表按钮, 同时记下扫描的日期(yyyymmdd格式, 如20240118)
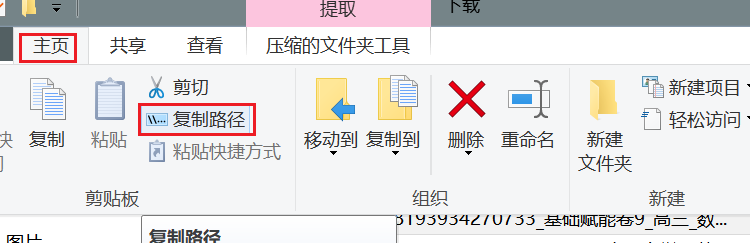
- 稍后找到下载文件的路径, 在windows的资源管理器中选中该文件, 点菜单栏上的
主页-复制路径(win11可直接右键后在菜单中选择)
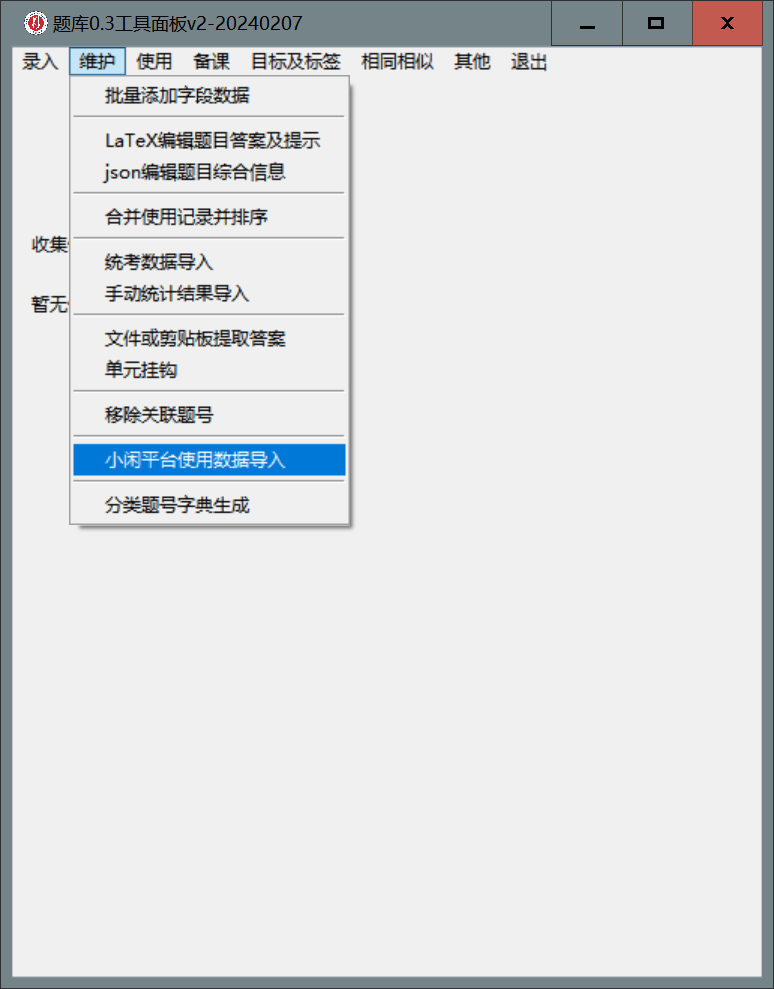
- 在面板上选择
维护-小闲平台使用数据导入
- 在
vscode打开的config.json文件的收集使用记录.py部分进行编辑, 方式见下图
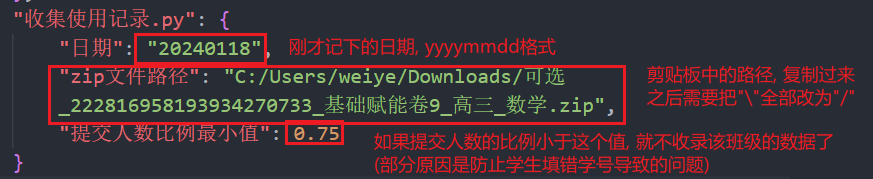
- 编辑完成后保存并关闭
config.json, 点击面板上的运行按钮, 将生成文本文件/metadata.txt并在vscode中打开. 建议将该文件用提交issue的方式发给管理员, 管理员可以用维护-批量添加字段数据功能将信息导入到题库0.3/Problems.json数据库, 如果仅仅是为了测试, 可以自行操作后在git面板中观察Problems.json文件在导入前后的变化
添加基础知识梳理
因可能有冲突, 故建议该项工作完全由管理员进行, 备课组负责人整理完成后在gitlab上提issue
TBD